Vektorsuche und im weiteren Sinne künstliche Intelligenz (KI) sind heute beliebter denn je. Diese Begriffe tauchen überall auf. Technologieunternehmen auf der ganzen Welt bemühen sich darum, Vektorsuche und KI-Funktionen zu veröffentlichen, um Teil dieses wachsenden Trends zu sein. Daher ist es ungewöhnlich, auf die Homepage eines datengesteuerten Unternehmens zu stoßen, ohne einen Verweis auf die Vektorsuche oder große Sprachmodelle (LLMs) zu finden. In diesem Blog befassen wir uns mit der MEAN dieser Begriffe und untersuchen gleichzeitig die Ereignisse, die zu ihrem aktuellen Trend geführt haben.
Schauen Sie sich unsere KI-Ressourcenseite an, um mehr über die Erstellung KI-gestützter Apps mit MongoDB zu erfahren.
Was ist Vector Search?
Vektoren sind codierte Darstellungen unstrukturierter Daten wie Text, Bilder und Audio in Form eines Array.
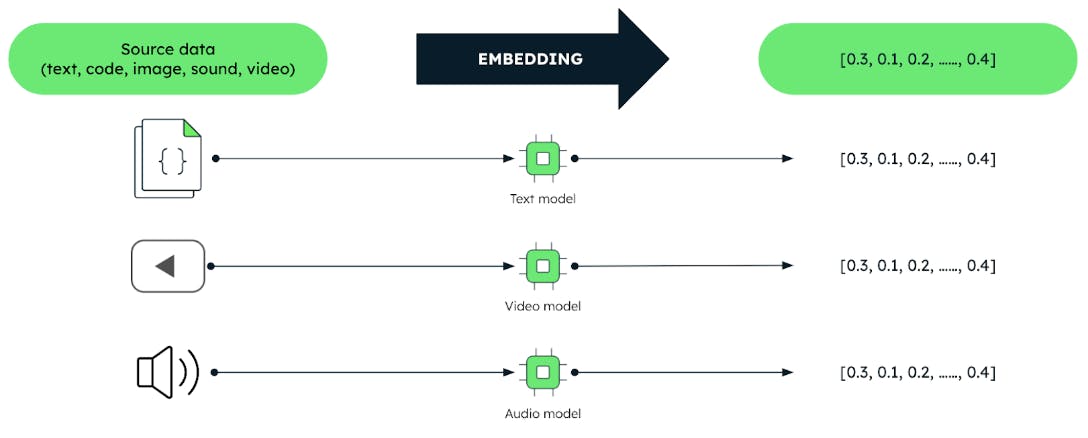
Diese Vektoren werden durch Techniken des maschinellen Lernens (ML) erzeugt, die als „Einbettungsmodelle“ bezeichnet werden. Diese Modelle werden auf großen Datenmengen trainiert. Einbettungsmodelle erfassen effektiv sinnvolle Beziehungen und Ähnlichkeiten zwischen Daten. Dies ermöglicht es Benutzern, Daten basierend auf der Bedeutung und nicht auf der Grundlage der Daten selbst abzufragen. Diese Tatsache ermöglicht effizientere Datenanalyseaufgaben wie Empfehlungssysteme, Sprachverständnis und Bilderkennung.
Jede Suche beginnt mit einer Abfrage und bei der Vector Search wird die Abfrage durch einen Vektor dargestellt. Die Aufgabe der Vektorsuche besteht darin, aus den in einer Datenbank gespeicherten Vektoren diejenigen zu finden, die dem Vektor der Abfrage am ähnlichsten sind. Dies ist die Grundvoraussetzung. Es geht um Ähnlichkeit. Aus diesem Grund wird die Vektorsuche oft als Ähnlichkeitssuche bezeichnet. Hinweis: Ähnlichkeit gilt auch für Ranking-Algorithmen, die mit Nicht-Vektordaten arbeiten.
Um das Konzept der Vektorähnlichkeit zu verstehen, stellen wir uns einen dreidimensionalen Raum vor. In diesem Raum wird die Position eines Datenpunkts vollständig durch drei Koordinaten bestimmt.
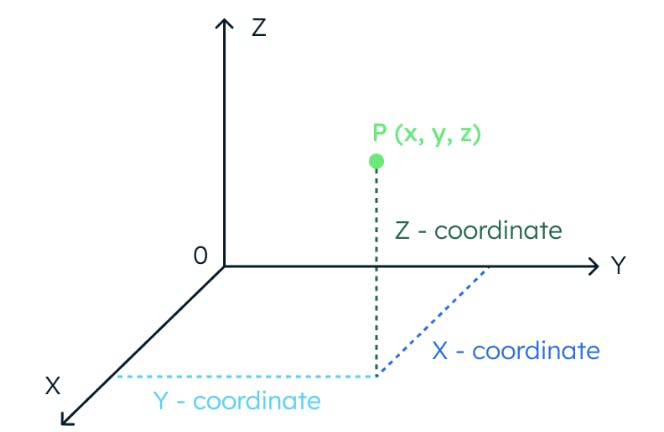
Wenn ein Raum 1024 Dimensionen hat, sind auf die gleiche Weise 1024 Koordinaten erforderlich, um einen Datenpunkt zu lokalisieren.
Vektoren liefern auch die Position von Datenpunkten in mehrdimensionalen Räumen. Tatsächlich können wir die Werte in einem Vektor als ein Array behandeln. Sobald wir die Position der Datenpunkte – der Vektoren – haben, wird ihre Ähnlichkeit untereinander berechnet, indem der Abstand zwischen ihnen im Vektorraum gemessen wird. Punkte, die im Vektorraum näher beieinander liegen, stellen Konzepte dar, deren Bedeutung ähnlicher ist.
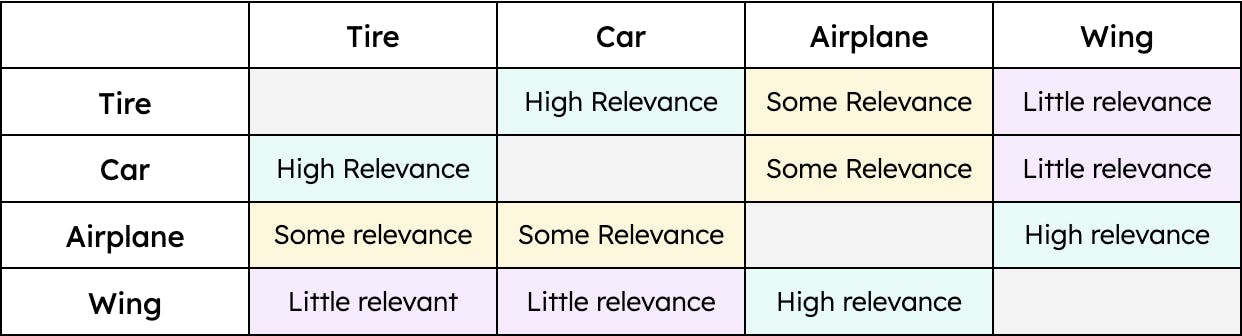
Beispielsweise hat „Reifen“ eine größere Ähnlichkeit mit „Auto“ und eine geringere Ähnlichkeit mit „Flugzeug“. Allerdings hätte „Flügel“ nur eine Ähnlichkeit mit „Flugzeug“. Daher wäre der Abstand zwischen den Vektoren für „Reifen“ und „Auto“ kleiner als der Abstand zwischen den Vektoren für „Reifen“ und „Flugzeug“. Allerdings wäre der Abstand zwischen „Flügel“ und „Auto“ enorm. Mit anderen Worten: „Reifen“ ist relevant, wenn wir von einem „Auto“ und in geringerem Maße von einem „Flugzeug“ sprechen. Allerdings ist ein „Flügel“ nur relevant, wenn wir von einem „Flugzeug“ sprechen, und überhaupt nicht relevant, wenn wir von einem „Auto“ sprechen (zumindest bis fliegende Autos ein brauchbares Transportmittel sind). Die Kontextualisierung von Daten – unabhängig vom Typ – ermöglicht es der Vector Search, die relevantesten Ergebnisse zu einer bestimmten Abfrage abzurufen.
Ein einfaches Beispiel für Ähnlichkeit
Was sind große Sprachmodelle?
LLMs bringen KI in die Vektorsuchgleichung ein. LLMs und der menschliche Geist verstehen und assoziieren Konzepte, um bestimmte Aufgaben in natürlicher Sprache auszuführen, beispielsweise einem Gespräch zu folgen oder einen Artikel zu verstehen. LLMs benötigen wie Menschen eine Ausbildung, um verschiedene Konzepte zu verstehen. Wissen Sie zum Beispiel, was der Begriff „Corium“ bedeutet? Es sei denn, Sie sind Nuklearingenieur, wahrscheinlich nicht. Das Gleiche gilt für LLMs: Wenn sie nicht in einem bestimmten Bereich ausgebildet sind, sind sie nicht in der Lage, Konzepte zu verstehen und erbringen daher schlechte Leistungen. Schauen wir uns ein Beispiel an.
LLMs verstehen Textteile dank ihrer Einbettungsschicht. Dabei werden Wörter oder Sätze in Vektoren umgewandelt. Um Vektoren zu visualisieren, verwenden wir die cloud. cloud sind eng mit Vektoren verwandt, da sie Konzepte und deren Kontext darstellen. Sehen wir uns zunächst die cloud an, die ein Einbettungsmodell für den Begriff „Corium“ erzeugen würde, wenn es mit kerntechnischen Daten trainiert würde:

Wie im Bild oben gezeigt, weist die cloud darauf hin, dass es sich bei Corium um ein radioaktives Material handelt, das etwas mit Sicherheits- und Eindämmungsstrukturen zu tun hat. Corium ist jedoch ein spezieller Begriff, der auch auf einen anderen Bereich angewendet werden kann. Sehen wir uns die cloud an, die sich aus einem Einbettungsmodell ergibt, das in Biologie und Anatomie trainiert wurde:
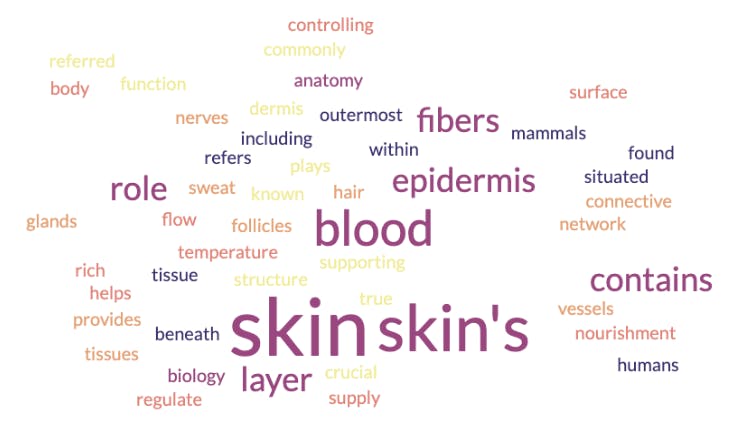
In diesem Fall weist die cloud darauf hin, dass es sich bei Corium um einen Begriff handelt, der sich auf die Haut und ihre Schichten bezieht. Was ist hier passiert? Ist eines der Einbettungsmodelle falsch? NEIN. Sie wurden beide mit unterschiedlichen Datenfestlegungen trainiert. Deshalb ist es entscheidend, das am besten geeignete Modell für einen bestimmten Anwendungsfall zu finden. Eine gängige Praxis in der Branche ist die Übernahme eines vorab trainierten Einbettungsmodells mit fundiertem Hintergrundwissen. Man nimmt dieses Modell und passt es dann mit dem domänenspezifischen Wissen an, das zur Ausführung bestimmter Aufgaben erforderlich ist.
Auch die Quantität und Qualität der zum Trainieren eines Modells verwendeten Daten sind relevant. Wir sind uns einig, dass eine Person, die nur einen Artikel über Aerodynamik gelesen hat, über das Thema weniger informiert ist als eine Person, die Physik und Luft- und Raumfahrttechnik studiert hat. Ebenso sind Modelle, die mit großen Mengen an qualitativ hochwertigen Daten trainiert werden, besser in der Lage, Konzepte zu verstehen und Vektoren zu generieren, die sie genauer darstellen. Dies schafft die Grundlage für ein erfolgreiches Vektorsuchsystem.
Es ist erwähnenswert, dass LLMs zwar Texteinbettungsmodelle verwenden, die Vektorsuche jedoch darüber hinausgeht. Es kann mit Audio, Bildern und mehr umgehen. Es ist wichtig zu bedenken, dass die für diese Fälle verwendeten Einbettungsmodelle denselben Ansatz verfolgen. Sie müssen auch mit Daten – Bildern, Tönen usw. – trainiert werden, um die Bedeutung dahinter zu verstehen und die entsprechenden Ähnlichkeitsvektoren zu erstellen.
Wann wurde die Vector Search erstellt?
MongoDB Atlas Vector Search bietet derzeit drei Ansätze zur Berechnung der Vektorähnlichkeit. Diese werden auch als Distanzmetriken bezeichnet und bestehen aus:
-
Euklidische Entfernung
-
Kosinusprodukt
-
Skalarprodukt
Obwohl jede Metrik anders ist, konzentrieren wir uns in diesem Blog auf die Tatsache, dass sie alle die Entfernung messen. Atlas Vector Search speist diese Distanzmetriken in einen ANN-Algorithmus (Approximation Nearest Neighbor) ein, um die gespeicherten Vektoren zu finden, die dem Vektor der Abfrage am ähnlichsten sind. Um diesen Prozess zu beschleunigen, werden Vektoren mithilfe eines Algorithmus namens „Hierarchical Navigable Small World“ (HNSW) Index . HNSW leitet die Suche durch ein Netzwerk miteinander verbundener Datenpunkte, sodass nur die relevantesten Datenpunkte berücksichtigt werden.
Die Verwendung einer der drei Distanzmetriken in Verbindung mit den HNSW- und KNN-Algorithmen bildet die Grundlage für die Durchführung einer Vektorsuche im MongoDB Atlas. Aber wie alt sind diese Technologien? Wir würden denken, dass es sich um neue Erfindungen eines hochmodernen Quantencomputerlabors handelt, aber die Wahrheit ist weit davon entfernt.
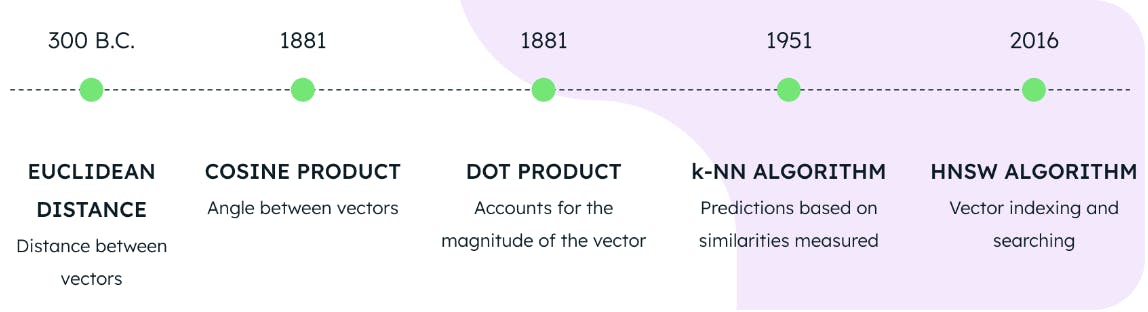
Der euklidische Abstand wurde im Jahr 300 v. Chr. formuliert, der Kosinus und das Skalarprodukt im Jahr 1881, der KNN-Algorithmus im Jahr 1951 und der HNSW-Algorithmus im Jahr 2016. Dies bedeutet, dass die Grundlagen für eine moderne Vektorsuche bereits im Jahr 2016 vollständig vorhanden waren. Obwohl die Vektorsuche heute ein heißes Thema ist, ist es bereits seit mehreren Jahren möglich, sie umzusetzen.
Wann wurden LLMs erstellt?
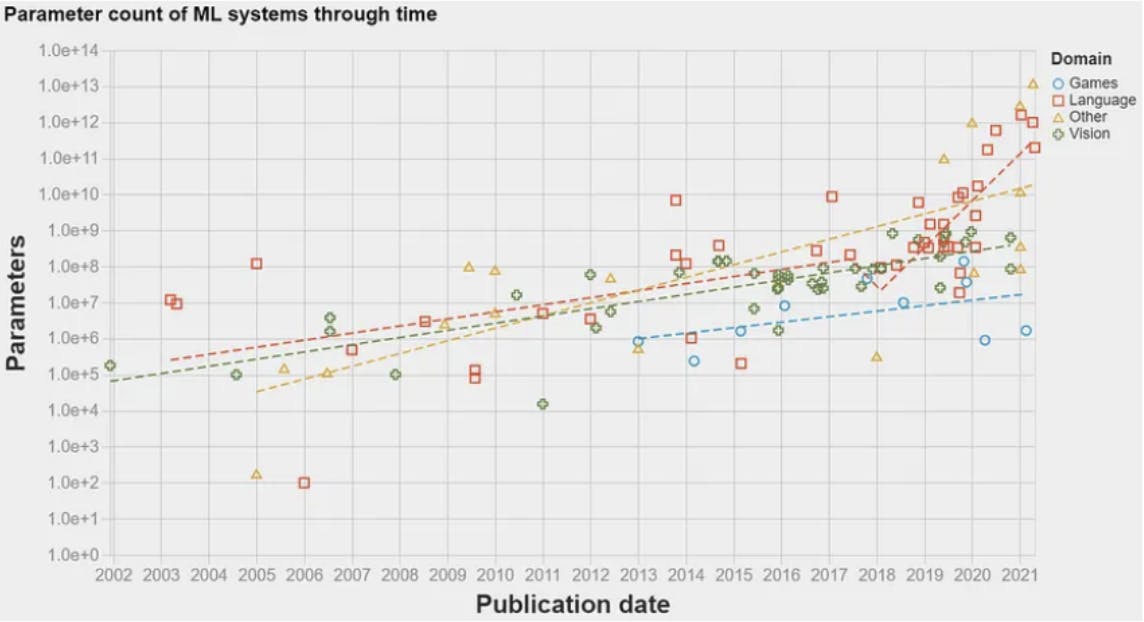
Im Jahr 2017 gab es einen Durchbruch: die Transformer-Architektur. Diese Architektur wurde in dem berühmten Artikel Attention is all you need vorgestellt und führte ein neuronales Netzwerkmodell für NLP-Aufgaben (Natural Language Processing) ein. Dies ermöglichte es ML-Algorithmen, Sprachdaten in einer Größenordnung zu verarbeiten, die zuvor möglich war. Dadurch nahm die Menge an Informationen, die zum Trainieren der Modelle verwendet werden konnte, exponentiell zu. Dies ebnete den Weg für das Erscheinen des ersten LLM im Jahr 2018: GPT-1 von OpenAI. LLMs verwenden Einbettungsmodelle, um Textteile zu verstehen und bestimmte Aufgaben in natürlicher Sprache wie die Beantwortung von Fragen oder maschinelle Übersetzung auszuführen. LLMs sind im Wesentlichen NLP-Modelle, die aufgrund der großen Datenmenge, mit der sie trainiert werden, umbenannt wurden – daher das Wort „groß“ in LLM. Die folgende Graph zeigt die Datenmenge – Parameter –, die im Laufe der Jahre zum Trainieren von ML-Modellen verwendet wurde. Ein dramatischer Anstieg ist im Jahr 2017 nach Veröffentlichung der Transformer-Architektur zu beobachten.
Warum sind Vektorsuche und LLMs so beliebt?
Wie bereits erwähnt, war die Technologie zur Vektorsuche bereits im Jahr 2016 vollständig verfügbar. Besonders beliebt wurde es allerdings erst Ende 2022. Warum?
Obwohl die ML-Branche seit 2018 sehr aktiv ist, waren LLMs bis zur Veröffentlichung von ChatGPT durch OpenAI im November 2022 weder allgemein verfügbar noch einfach zu verwenden. Die Tatsache, dass OpenAI jedem die Interaktion mit einem LLM über einen einfachen Chat ermöglichte, ist der Schlüssel zu seinem Erfolg. ChatGPT revolutionierte die Branche, indem es dem Durchschnittsbürger ermöglichte, mit NLP-Algorithmen auf eine Weise zu interagieren, die sonst Forschern und Wissenschaftlern vorbehalten gewesen wäre. Wie in der folgenden Abbildung zu sehen ist, führte der Durchbruch von OpenAI zu einem rasanten Anstieg der Popularität von LLMs. Gleichzeitig wurde ChatGPT zu einem Mainstream-Tool, das von der breiten Öffentlichkeit genutzt wird. Der Einfluss von OpenAI auf die Popularität von LLMs wird auch durch die Tatsache belegt, dass sowohl OpenAI als auch LLMs gleichzeitig ihren ersten Popularitätshöhepunkt erreichten. (Siehe Abbildung 8.)
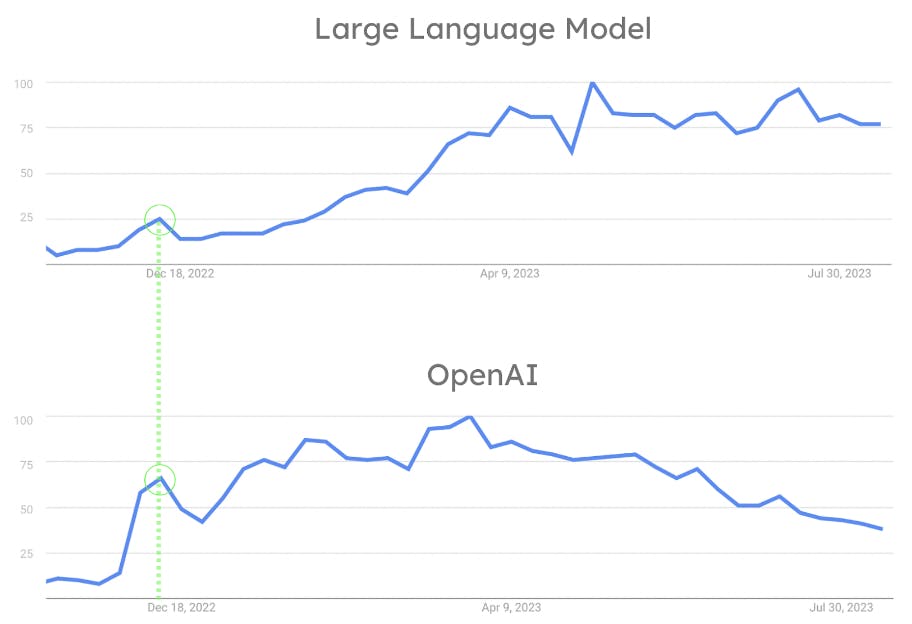
Hier erfahren Sie, warum. LLMs sind so beliebt, weil OpenAI sie mit der Veröffentlichung von ChatGPT berühmt gemacht hat. Das Suchen und Speichern großer Mengen an Vektoren wurde zu einer Herausforderung. Dies liegt daran, dass LLMs mit Einbettungen arbeiten. Damit nahm gleichzeitig auch die Einführung der Vektorsuche zu. Dies ist der größte Faktor, der zum Branchenwandel beiträgt. Dieser Wandel führte dazu, dass viele Datenunternehmen Unterstützung für die vector search und andere Funktionen im Zusammenhang mit LLMs und der dahinter stehenden KI einführten.
Fazit
Die Vektorsuche ist ein moderner Disruptor. Der zunehmende Wert sowohl von Vektoreinbettungen als auch fortgeschrittener mathematischer Suchprozesse hat die Einführung der Vektorsuche beschleunigt und den Bereich der Informationsbeschaffung verändert. Vektorgenerierung und Vektorsuche mögen zwar unabhängige Prozesse sein, aber wenn sie zusammenarbeiten, ist ihr Potenzial grenzenlos.
Um mehr zu erfahren, besuchen Sie unsere Atlas Vector Search-Produktseite. Um mit Vector Search zu beginnen, melden Sie sich bei Atlas an oder anmeldung bei Ihrem Konto an.