La recherche vectorielle et, plus largement, l'intelligence artificielle (IA) sont plus populaires que jamais. Ces termes apparaissent partout. Les entreprises technologiques du monde entier s'efforcent de mettre au point des fonctionnalités de recherche vectorielle et d'IA afin de participer à cette tendance croissante. Par conséquent, il est rare de tomber sur la page d'accueil d'une entreprise axée sur les données sans voir une référence à la recherche vectorielle ou aux grands modèles de langage (LLM). Dans ce blog, nous verrons ce que sont ces termes MEAN et nous examinerons les événements qui ont conduit à leur popularité actuelle.
Consultez notre page de ressources sur l'IA pour en savoir plus sur la création d'applications basées sur l'IA avec MongoDB.
Qu'est-ce que la recherche vectorielle ?
Les vecteurs sont des représentations codées de données non structurées telles que du texte, des images et du son sous la forme d'une gamme de nombres.
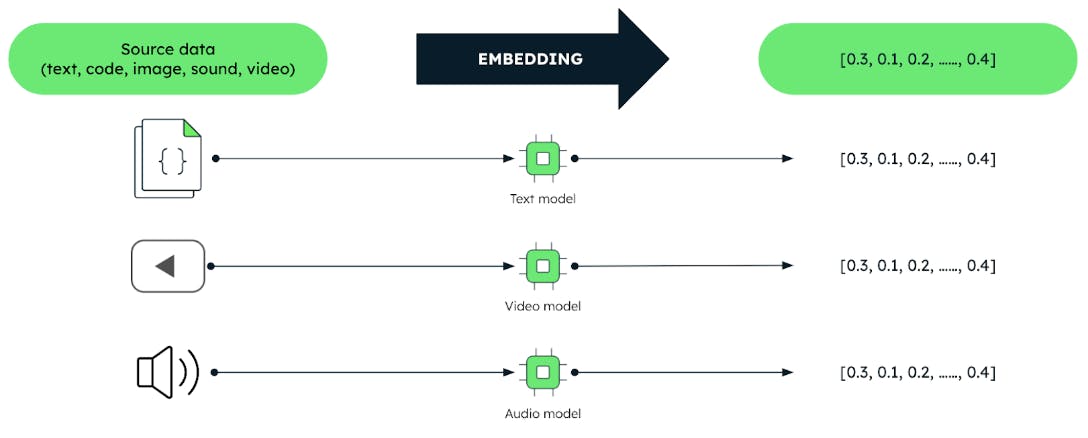
Ces vecteurs sont produits par des techniques d'apprentissage automatique appelées "embedding models". Ces modèles sont entraînés sur de grands corpus de données. Les modèles d'intégration permettent de saisir efficacement les relations et les similitudes significatives entre les données. Cela permet aux utilisateurs d'interroger les données en se basant sur la signification plutôt que sur les données elles-mêmes. Cela permet de réaliser des tâches d'analyse de données plus efficaces, telles que les systèmes de recommandation, la compréhension du langage et la reconnaissance d'images.
Toute recherche commence par une requête et, dans la recherche vectorielle, la requête est représentée par un vecteur. La recherche vectorielle consiste à trouver, parmi les vecteurs stockés dans une base de données, ceux qui sont les plus similaires au vecteur de la requête. C'est le principe de base. Il s'agit d'une question de similitude. C'est pourquoi la recherche vectorielle est souvent appelée recherche de similarité. Remarque : la similitude s'applique également aux algorithmes de classement qui utilisent des données non vectorielles.
Pour comprendre le concept de similarité vectorielle, imaginons un espace à trois dimensions. Dans cet espace, l'emplacement d'un point de données est entièrement déterminé par trois coordonnées.
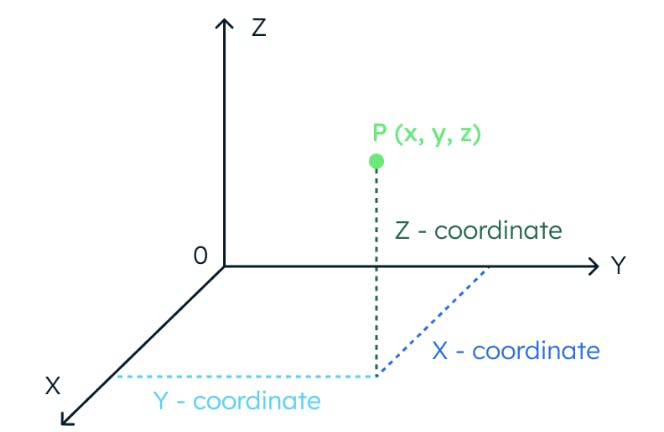
De même, si un espace a 1024 dimensions, il faut 1024 coordonnées pour localiser un point de données.
Les vecteurs permettent également de localiser des points de données dans des espaces multidimensionnels. En fait, nous pouvons traiter les valeurs d'un vecteur comme une gamme de coordonnées. Une fois que nous avons localisé les points de données - les vecteurs - leur similarité est calculée en mesurant la distance qui les sépare dans l'espace vectoriel. Les points les plus proches les uns des autres dans l'espace vectoriel représentent des concepts dont la signification est plus proche.
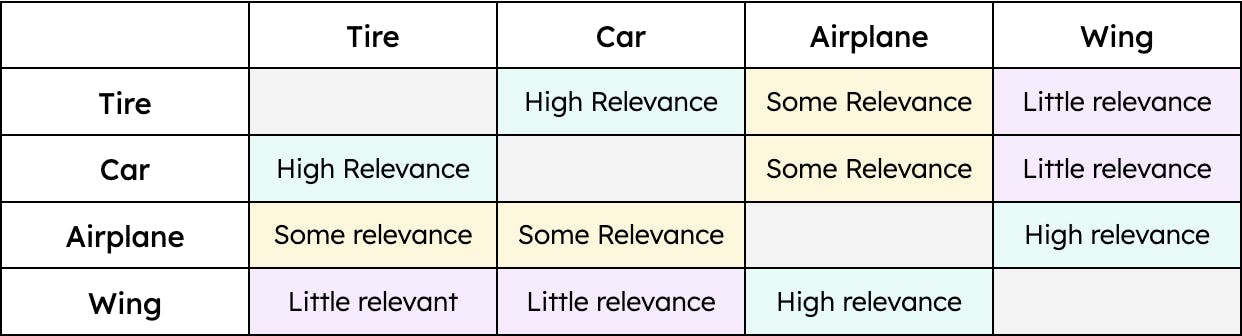
Par exemple, "pneu" a une plus grande similitude avec "voiture" et une moindre avec "avion." Cependant, l'aile "" n'aurait qu'une similarité avec l'avion "." Par conséquent, la distance entre les vecteurs "pneu" et "voiture" serait plus petite que la distance entre les vecteurs "pneu" et "avion". Pourtant, la distance entre "aile" et "voiture" serait énorme. En d'autres termes, le terme "pneu" est pertinent lorsque l'on parle d'une "voiture" et, dans une moindre mesure, d'un "avion". Cependant, une "aile" n'est pertinente que lorsqu'il s'agit d'un "avion" et ne l'est pas du tout lorsqu'il s'agit d'une "voiture" (du moins jusqu'à ce que les voitures volantes deviennent un mode de transport viable). La contextualisation des données - quel qu'en soit le type - permet à la recherche vectorielle d'extraire les résultats les plus pertinents pour une requête donnée.
Un exemple simple de similarité
Que sont les grands modèles linguistiques ?
Les LLM apportent l'IA à l'équation de la recherche vectorielle. Les LLM et les esprits humains comprennent et associent tous deux des concepts afin d'effectuer certaines tâches en langage naturel, comme suivre une conversation ou comprendre un article. Les LLM, comme les humains, ont besoin d'être formés pour comprendre différents concepts. Par exemple, savez-vous à quoi correspond le terme "corium" ? À moins d'être ingénieur nucléaire, probablement pas. Il en va de même pour les LLM : s'ils ne sont pas formés dans un domaine spécifique, ils ne sont pas en mesure de comprendre les concepts et obtiennent donc de mauvais résultats. Prenons un exemple.
Les LLM comprennent des morceaux de texte grâce à leur couche d'intégration. C'est ici que les mots ou les phrases sont convertis en vecteurs. Pour visualiser les vecteurs, nous allons utiliser le mot cloud. Les mots cloud sont étroitement liés aux vecteurs en ce sens qu'ils représentent des concepts et leur contexte. Voyons tout d'abord le mot cloud qu'un modèle d'intégration générerait pour le terme "corium" s'il était entraîné avec des données d'ingénierie nucléaire :

Comme le montre l'image ci-dessus, le mot cloud indique que le corium est un matériau radioactif qui a un rapport avec les structures de sécurité et de confinement. Mais le corium est un terme particulier qui peut également s'appliquer à un autre domaine. Voyons le mot cloud résultant d'un modèle d'intégration formé à la biologie et à l'anatomie :
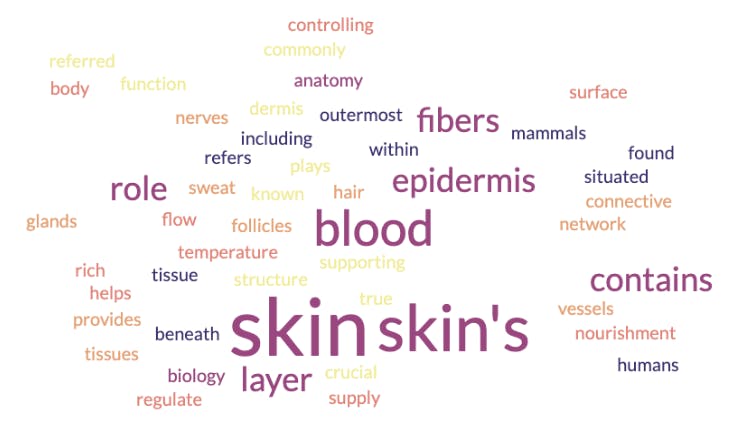
Dans ce cas, le mot cloud indique que le corium est un concept lié à la peau et à ses couches. Que s'est-il passé ici ? L'un des modèles d'intégration est-il erroné ? Non. Ils ont tous deux été formés avec des données différentes. C'est pourquoi il est essentiel de trouver le modèle le plus approprié pour un cas d'utilisation spécifique. Une pratique courante dans l'industrie consiste à adopter un modèle d'intégration pré-entraîné avec de solides connaissances de base. On prend ce modèle et on l'affine ensuite avec les connaissances spécifiques au domaine nécessaires à l'exécution de tâches particulières.
La quantité et la qualité des données utilisées pour former un modèle sont également importantes. Nous pouvons convenir qu'une personne qui n'a lu qu'un seul article sur l'aérodynamique sera moins bien informée sur le sujet qu'une personne qui a étudié la physique et l'ingénierie aérospatiale. De même, les modèles formés à partir d'un grand nombre de données de haute qualité comprennent mieux les concepts et génèrent des vecteurs qui les représentent plus fidèlement. C'est la base d'un système de recherche vectorielle efficace.
Il convient de noter que, bien que les LLM utilisent des modèles d'intégration de texte, la recherche vectorielle va plus loin. Il peut traiter des fichiers audio, des images et bien d'autres choses encore. Il est important de rappeler que les modèles d'intégration utilisés dans ces cas partagent la même approche. Ils doivent également être formés aux données - images, sons, etc. - afin de pouvoir en comprendre le sens et créer les vecteurs de similarité appropriés.
Quand la recherche vectorielle a-t-elle été créée ?
MongoDB Atlas Vector Search propose actuellement trois approches pour calculer la similarité des vecteurs. Ces mesures sont également appelées "mesures de distance" et consistent en :
-
distance euclidienne
-
produit du cosinus
-
produit en points
Bien que chaque mesure soit différente, pour les besoins de ce blog, nous nous concentrerons sur le fait qu'elles mesurent toutes la distance. Atlas Vector Search introduit ces mesures de distance dans un algorithme de voisinage approximatif le plus proche (ANN) pour trouver les vecteurs stockés qui sont les plus similaires au vecteur de la requête. Afin d'accélérer ce processus, les vecteurs sont indexés à l'aide d'un algorithme appelé "petit monde navigable hiérarchique" (HNSW). HNSW guide la recherche à travers un réseau de points de données interconnectés afin que seuls les points de données les plus pertinents soient pris en compte.
L'utilisation de l'une des trois mesures de distance en conjonction avec les algorithmes HNSW et KNN constitue la base de la recherche vectorielle sur MongoDB Atlas. Mais quelle est l'ancienneté de ces technologies ? On pourrait croire qu'il s'agit d'inventions récentes d'un laboratoire d'informatique quantique de pointe, mais la vérité est loin d'être là.
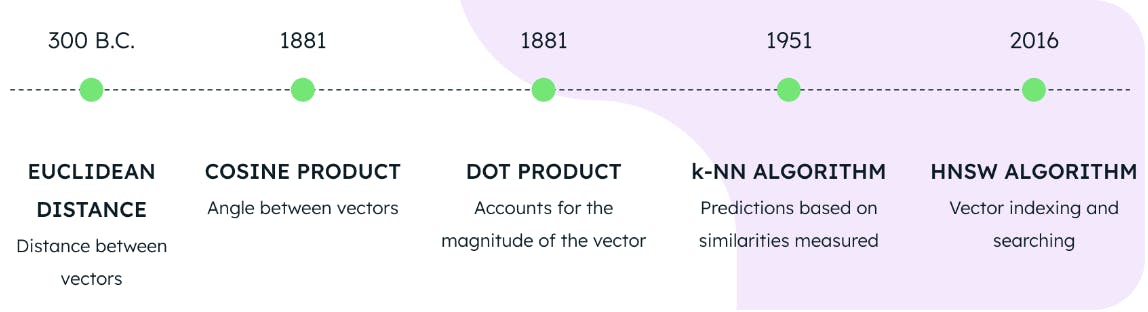
La distance euclidienne a été formulée en 300 avant J.-C., le cosinus et le produit du point en 1881, l'algorithme KNN en 1951 et l'algorithme HNSW en 2016. Cela signifie que les bases de la recherche vectorielle de pointe étaient déjà disponibles en 2016. Ainsi, bien que la recherche vectorielle soit un sujet d'actualité, il est possible de la mettre en œuvre depuis plusieurs années.
Quand les LLM ont-ils été créés ?
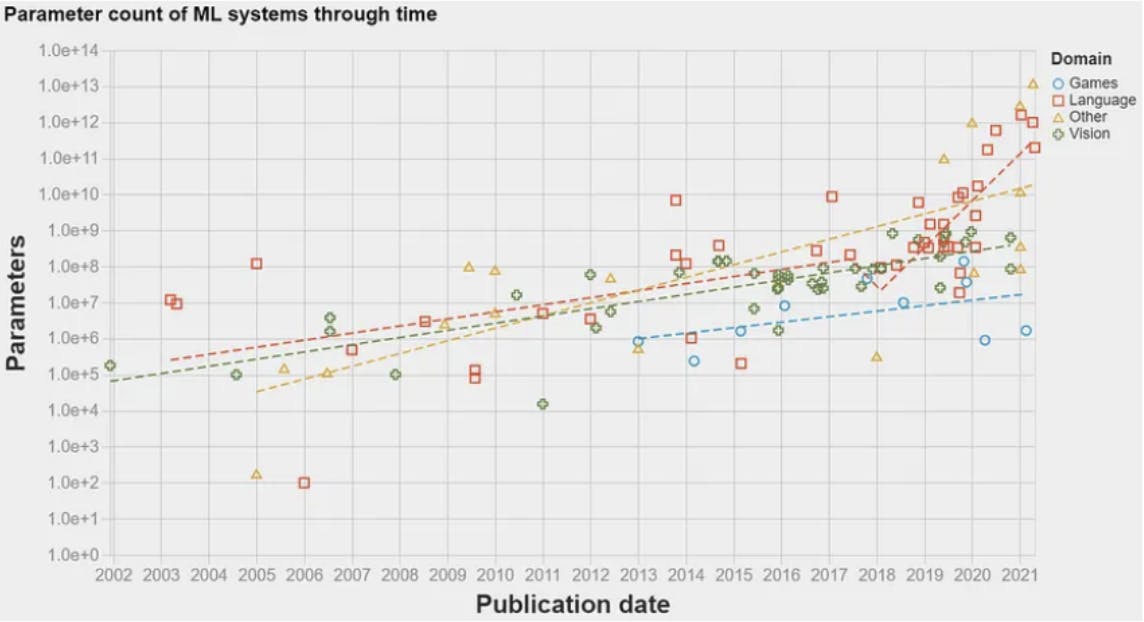
En 2017, il y a eu une percée : l'architecture du transformateur. Présentée dans le célèbre article Attention is all you need, cette architecture a introduit un modèle de réseau neuronal pour les tâches de traitement du langage naturel (NLP). Cela a permis aux algorithmes de ML de traiter les données linguistiques dans un ordre de grandeur supérieur à ce qui était possible auparavant. Par conséquent, la quantité d'informations pouvant être utilisées pour former les modèles a augmenté de façon exponentielle. Cela a ouvert la voie à l'apparition du premier LLM en 2018 : GPT-1 par OpenAI. Les LLM utilisent des modèles d'intégration pour comprendre des morceaux de texte et effectuer certaines tâches en langage naturel, comme la réponse à des questions ou la traduction automatique. Les LLM sont essentiellement des modèles de NLP qui ont été rebaptisés en raison de la grande quantité de données avec lesquelles ils sont entraînés - d'où le mot "large" dans LLM. Le graphique ci-dessous montre la quantité de données - paramètres - utilisées pour former les modèles de ML au fil des ans. Une augmentation spectaculaire peut être observée en 2017 après la publication de l'architecture du transformateur.
Pourquoi la Vector Search et les LLM sont-ils si populaires ?
Comme indiqué plus haut, la technologie de la recherche vectorielle était pleinement disponible en 2016. Cependant, il n'est devenu particulièrement populaire qu'à la fin de l'année 2022. Pourquoi ?
Bien que l'industrie des ML soit très active depuis 2018, les LLM n'étaient pas largement disponibles ou faciles à utiliser jusqu'à la version de ChatGPT d'OpenAI en novembre 2022. Le fait qu'OpenAI ait permis à tout un chacun d'interagir avec un LLM par le biais d'un simple chat est la clé de son succès. ChatGPT a révolutionné le secteur en permettant au commun des mortels d'interagir avec les algorithmes NLP d'une manière qui aurait été autrement réservée aux chercheurs et aux scientifiques. Comme le montre la figure ci-dessous, la percée d'OpenAI a entraîné une montée en flèche de la popularité des LLM. Parallèlement, ChatGPT est devenu un outil grand public. L'influence de l'OpenAI sur la popularité des LLM est également démontrée par le fait que l'OpenAI et les LLM ont connu leur premier pic de popularité simultanément. (Voir figure 8.)
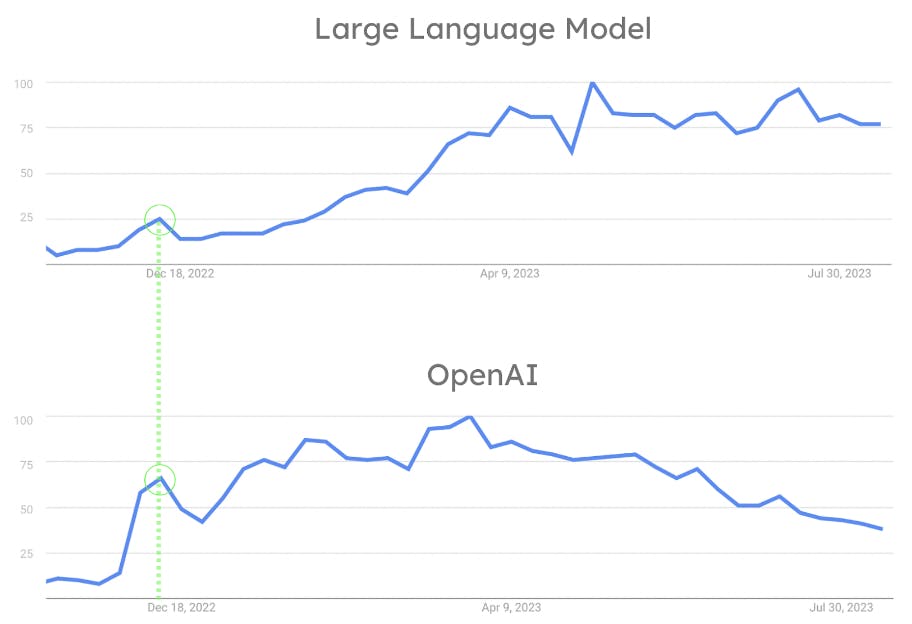
Voici pourquoi. Si les LLM sont si populaires, c'est parce qu'OpenAI les a rendus célèbres avec la version de ChatGPT. La recherche et le stockage de grandes quantités de vecteurs sont devenus un défi. Cela s'explique par le fait que les LLMs travaillent avec des encastrements. L'adoption de la recherche vectorielle a donc progressé parallèlement. C'est le facteur qui contribue le plus à la mutation du secteur. Cette évolution a conduit de nombreuses entreprises de données à introduire un support pour la recherche vectorielle et d'autres fonctionnalités liées aux LLM et à l'IA qui les sous-tend.
Conclusion
La recherche vectorielle est un perturbateur moderne. La valeur croissante des encastrements vectoriels et des processus de recherche mathématique avancés a catalysé l'adoption de la recherche vectorielle pour transformer le domaine de la recherche d'informations. La génération et la recherche de vecteurs peuvent être des processus indépendants, mais lorsqu'ils fonctionnent ensemble, leur potentiel est illimité.
Pour en savoir plus, visitez notre page produit Atlas Vector Search. Pour commencer à utiliser la Vector Search, inscrivez-vous à Atlas ou connectez-vous à votre compte.