Vector Search e, de forma mais ampla, a Inteligência Artificial (IA) são mais populares agora do que nunca. Esses termos estão surgindo em todos os lugares. As empresas de tecnologia em todo o mundo estão se esforçando para lançar recursos de pesquisa vetorial e IA em um esforço para fazer parte dessa tendência crescente. Como resultado, é incomum encontrar uma página inicial de uma empresa baseada em dados e não ver uma referência à pesquisa vetorial ou aos grandes modelos de linguagem (LLMs). Neste blog, abordaremos o que esses termos MEAN enquanto examinamos os eventos que levaram à sua tendência atual.
Confira nossa página de recursos de IA para saber mais sobre como criar aplicativos baseados em IA com MongoDB.
O que é pesquisa vetorial
Vetores são representações codificadas de dados não estruturados como texto, imagens e áudio na forma de matrizes de números.
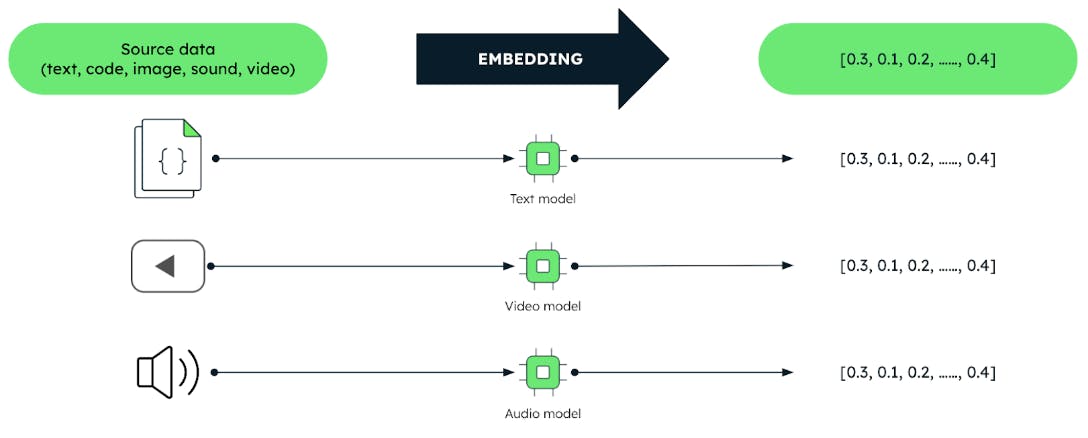
Esses vetores são produzidos por técnicas de aprendizado de máquina (ML) chamadas "modelos de incorporação". Esses modelos são treinados em grandes conjuntos de dados. A incorporação de modelos captura efetivamente relacionamentos e semelhanças significativas entre os dados. Isso permite que os usuários consultem dados com base no significado, e não nos dados em si. Este fato desbloqueia tarefas de análise de dados mais eficientes, como sistemas de recomendação, compreensão de linguagem e reconhecimento de imagem.
Toda pesquisa começa com uma consulta e, na vector search, a consulta é representada por um vetor. O trabalho da busca vetorial é encontrar, a partir dos vetores armazenados em um banco de dados, aqueles que mais se assemelham ao vetor da consulta. Esta é a premissa básica. É tudo uma questão de semelhança. É por isso que a vector search é frequentemente chamada de pesquisa por similaridade. Nota: a similaridade também se aplica a algoritmos de classificação que trabalham com dados não vetoriais.
Para entender o conceito de similaridade vetorial, vamos imaginar um espaço tridimensional. Neste espaço, a localização de um ponto de dados é totalmente determinada por três coordenadas.
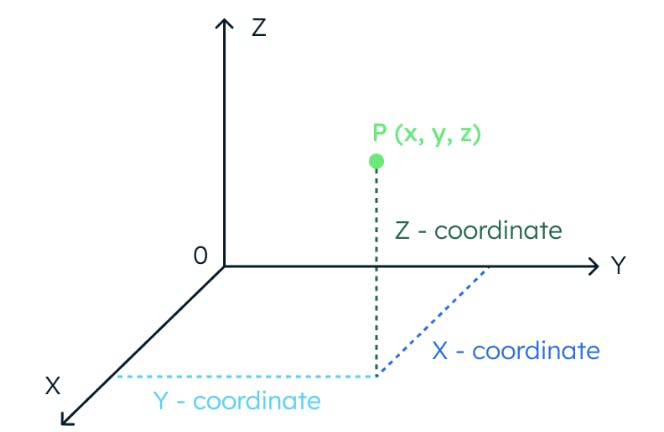
Da mesma forma, se um espaço tem 1.024 dimensões, são necessárias 1.024 coordenadas para localizar um ponto de dados.
Os vetores também fornecem a localização de pontos de dados em espaços multidimensionais. Na verdade, podemos tratar os valores de um vetor como uma matriz de coordenadas. Assim que tivermos a localização dos pontos de dados – os vetores – sua similaridade entre si é calculada medindo a distância entre eles no espaço vetorial. Os pontos mais próximos uns dos outros no espaço vetorial representam conceitos com significados mais semelhantes.
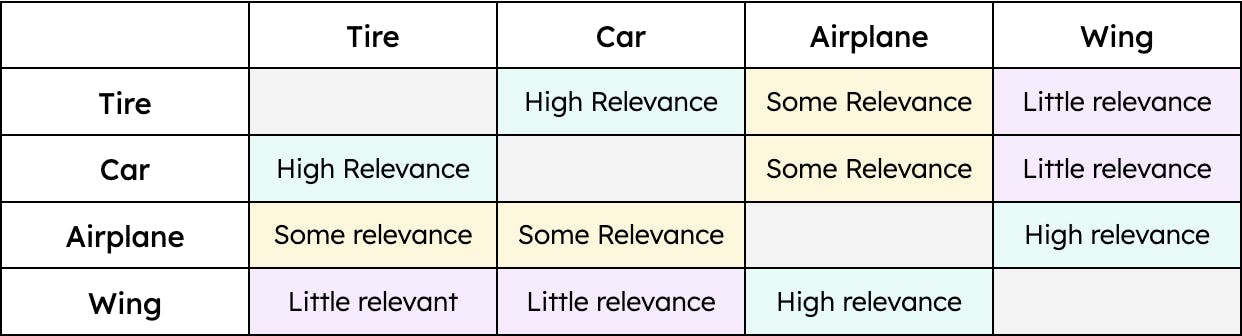
Por exemplo, “pneu” tem maior semelhança com “carro” e menor com “avião”. No entanto, “asa” teria apenas semelhança com “avião”. Portanto, a distância entre os vetores “pneu” e “carro” seria menor que a distância entre os vetores “pneu” e “avião”. No entanto, a distância entre “asa” e “carro” seria enorme. Em outras palavras, “pneu” é relevante quando falamos de “carro” e, em menor medida, de “avião”. No entanto, uma “asa” só é relevante quando falamos de um “avião” e não é de todo relevante quando falamos de um “carro” (pelo menos até que os carros voadores sejam um meio de transporte viável). A contextualização dos dados — independentemente do tipo — permite que a pesquisa vetorial recupere os resultados mais relevantes para uma determinada consulta.
Um exemplo simples de semelhança
O que são modelos de linguagem grande?
LLMs são o que trazem a IA para a equação de vector search. LLMs e mentes humanas entendem e associam conceitos para realizar certas tarefas de linguagem natural, como acompanhar uma conversa ou compreender um artigo. Os LLMs, assim como os humanos, precisam de treinamento para compreender diferentes conceitos. Por exemplo, você sabe a que se refere o termo “corium”? A menos que você seja um engenheiro nuclear, provavelmente não. O mesmo acontece com os LLMs: se não forem treinados em um domínio específico, não serão capazes de compreender conceitos e, portanto, terão um desempenho insatisfatório. Vejamos um exemplo.
LLMs entendem pedaços de texto graças à sua camada de incorporação. É aqui que palavras ou frases são convertidas em vetores. Para visualizar vetores, usaremos cloud de palavras. cloud de palavras está intimamente relacionada aos vetores no sentido de que são representações de conceitos e seu contexto. Primeiro, vamos ver a cloud de palavras que um modelo de incorporação geraria para o termo “corium” se fosse treinado com dados de engenharia nuclear:

Conforme mostrado na imagem acima, a palavra cloud indica que o cório é um material radioativo que tem algo a ver com estruturas de segurança e contenção. Mas cório é um termo especial que também pode ser aplicado a outro domínio. Vejamos a cloud de palavras resultante de um modelo de incorporação treinado em biologia e anatomia:
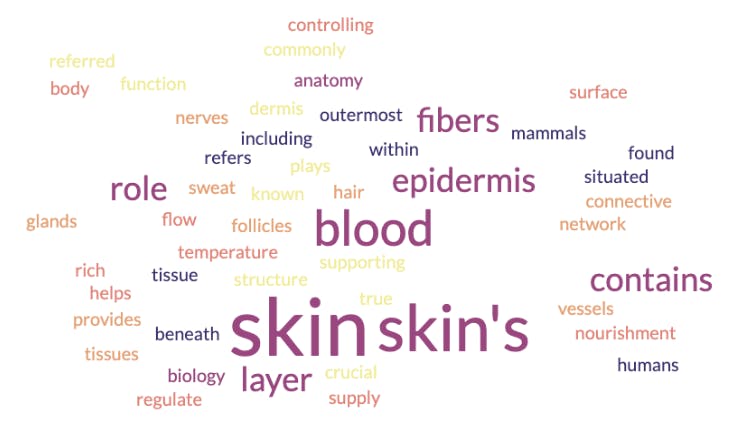
Nesse caso, a palavra cloud indica que cório é um conceito relacionado à pele e suas camadas. O que aconteceu aqui? Um dos modelos de incorporação está errado? Não. Ambos foram treinados com conjuntos de dados diferentes. É por isso que encontrar o modelo mais apropriado para um caso de uso específico é crucial. Uma prática comum na indústria é adotar um modelo de incorporação pré-treinado com forte conhecimento prévio. Pegamos esse modelo e o ajustamos com o conhecimento específico do domínio necessário para executar tarefas específicas.
A quantidade e a qualidade dos dados usados para treinar um modelo também são relevantes. Podemos concordar que quem leu apenas um artigo sobre aerodinâmica estará menos informado sobre o assunto do que quem estudou física e engenharia aeroespacial. Da mesma forma, os modelos treinados com grandes conjuntos de dados de alta qualidade serão melhores na compreensão de conceitos e na geração de vetores que os representem com mais precisão. Isso cria a base para um sistema de busca vetorial bem-sucedido.
É importante notar que embora os LLMs utilizem modelos de incorporação de texto, a vector search vai além disso. Ele pode lidar com áudio, imagens e muito mais. É importante lembrar que os modelos de incorporação utilizados para estes casos compartilham a mesma abordagem. Eles também precisam ser treinados com dados – imagens, sons, etc. – para serem capazes de compreender o significado por trás deles e criar os vetores de similaridade apropriados.
Quando a pesquisa vetorial foi criada?
O MongoDB Atlas Vector Search fornece atualmente três abordagens para calcular a similaridade vetorial. Eles também são chamados de métricas de distância e consistem em:
-
Distância euclidiana
-
Produto cosseno
-
Produto escalar
Embora cada métrica seja diferente, para o propósito deste blog, focaremos no fato de que todas medem distância. O Atlas Vector Search alimenta essas métricas de distância em um algoritmo de vizinho mais próximo aproximado (ANN) para encontrar os vetores armazenados que são mais semelhantes ao vetor da consulta. Para agilizar esse processo, os vetores são indexados por meio de um algoritmo denominado mundo pequeno navegável hierárquico (HNSW). O HNSW orienta a pesquisa através de uma rede de pontos de dados interconectados para que apenas os pontos de dados mais relevantes sejam considerados.
O uso de uma das três métricas de distância em conjunto com os algoritmos HNSW e KNN constitui a base para realizar a pesquisa vetorial no MongoDB Atlas. Mas, quantos anos têm essas tecnologias? Poderíamos pensar que são invenções recentes de um laboratório de computação quântica de última geração, mas a verdade está longe disso.
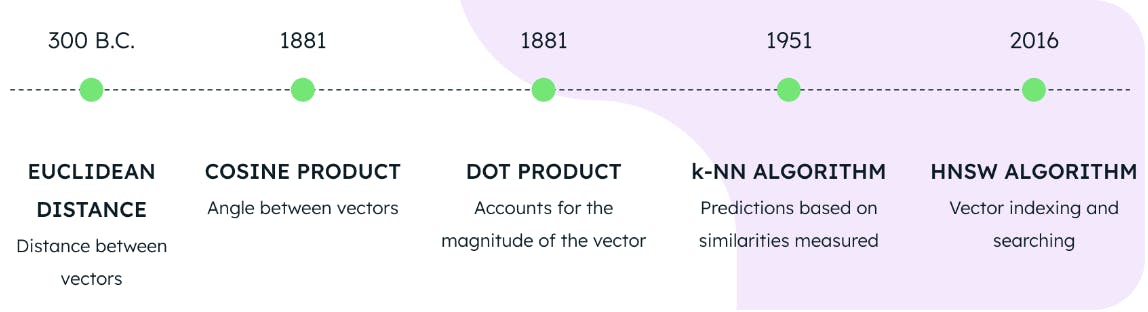
A distância euclidiana foi formulada no ano 300 a.C., o cosseno e o produto escalar em 1881, o algoritmo KNN em 1951 e o algoritmo HNSW em 2016. O que isto significa é que as bases para a pesquisa vetorial de última geração estavam totalmente disponíveis em 2016. Portanto, embora a pesquisa vetorial seja o tema quente da atualidade, já é possível implementá-la há vários anos.
Quando os LLMs foram criados?
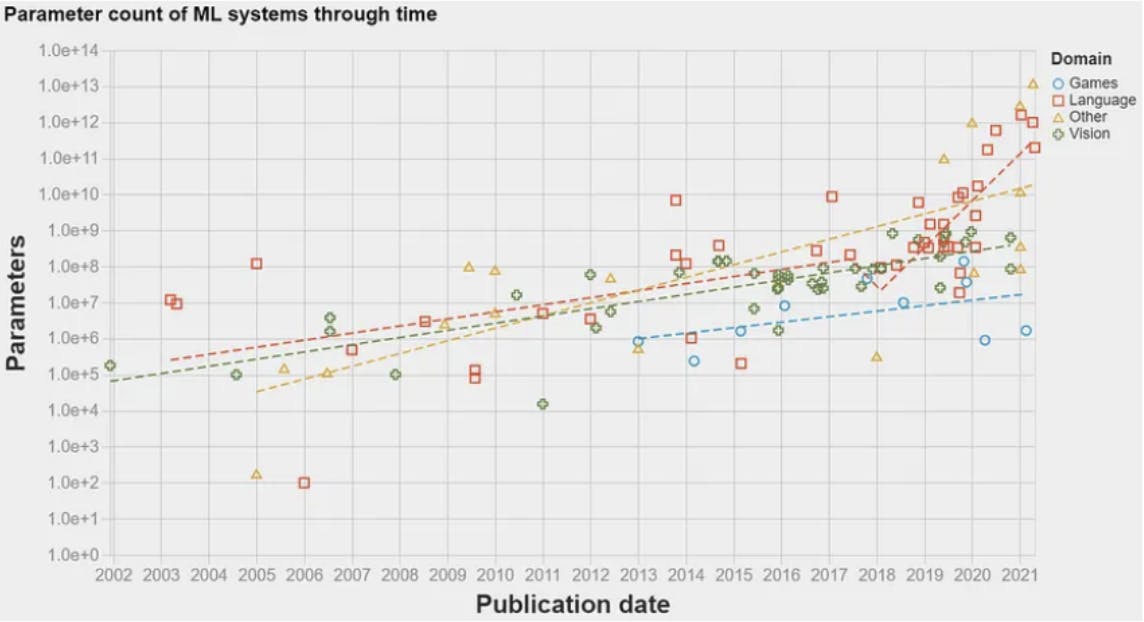
Em 2017, houve um grande avanço: a arquitetura do transformador. Apresentada no famoso artigo Attention is all you need, essa arquitetura introduziu um modelo de rede neural para tarefas de processamento de linguagem natural (PNL). Isso permitiu que algoritmos de ML processassem dados de linguagem em uma ordem de magnitude maior do que era possível anteriormente. Como resultado, a quantidade de informações que poderiam ser usadas para treinar os modelos aumentou exponencialmente. Isso abriu caminho para o primeiro LLM aparecer em 2018: GPT-1 da OpenAI. LLMs usam modelos de incorporação para compreender trechos de texto e realizar certas tarefas de linguagem natural, como resposta a perguntas ou tradução automática. LLMs são essencialmente modelos de PNL que foram renomeados devido à grande quantidade de dados com os quais são treinados – daí a palavra grande em LLM. O gráfico abaixo mostra a quantidade de dados — parâmetros — usados para treinar modelos de ML ao longo dos anos. Um aumento dramático pode ser observado em 2017, após a publicação da arquitetura do transformador.
Por que a pesquisa vetorial e os LLMs são tão populares?
Conforme afirmado acima, a tecnologia de busca vetorial estava totalmente disponível em 2016. No entanto, não se tornou particularmente popular até o final de 2022. Por que?
Embora a indústria de ML tenha estado muito ativa desde 2018, os LLMs não estavam amplamente disponíveis ou fáceis de usar até o lançamento do ChatGPT pela OpenAI em novembro de 2022. O fato de o OpenAI permitir que todos interajam com um LLM com um simples chat é a chave do seu sucesso. ChatGPT revolucionou a indústria ao permitir que uma pessoa comum interagisse com algoritmos de PNL de uma forma que de outra forma seria reservada para pesquisadores e cientistas. Como pode ser visto na figura abaixo, o avanço da OpenAI fez com que a popularidade dos LLMs disparasse. Ao mesmo tempo, o ChatGPT tornou-se uma ferramenta convencional usada pelo público em geral. A influência do OpenAI na popularidade dos LLMs também é evidenciada pelo fato de que tanto o OpenAI quanto os LLMs tiveram seu primeiro pico de popularidade simultaneamente. (Veja a figura 8.)
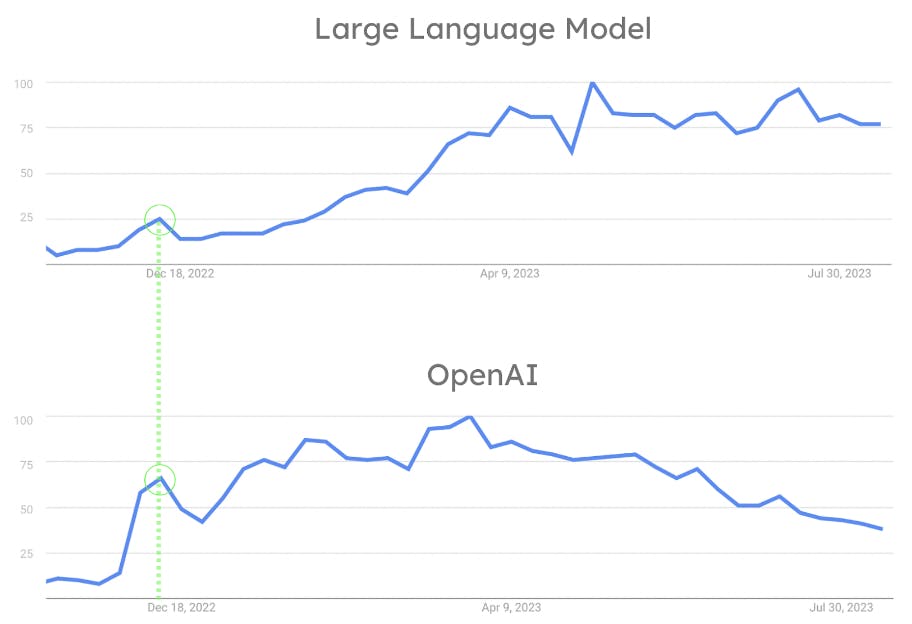
Aqui está o porquê. Os LLMs são tão populares porque a OpenAI os tornou famosos com o lançamento do ChatGPT. Pesquisar e armazenar grandes quantidades de vetores tornou-se um desafio. Isso ocorre porque os LLMs funcionam com incorporações. Assim, a adoção da busca vetorial aumentou paralelamente. Este é o maior fator que contribui para a mudança da indústria. Essa mudança resultou na introdução de suporte para pesquisa vetorial e outras funcionalidades relacionadas aos LLMs e à IA por trás deles, em muitas empresas de dados.
Conclusão
A pesquisa vetorial é um disruptor moderno. O valor crescente da incorporação de vetores e dos processos avançados de busca matemática catalisou a adoção da busca vetorial para transformar o campo da recuperação de informação. A geração e a busca de vetores podem ser processos independentes, mas quando trabalham juntas seu potencial é ilimitado.
Para saber mais, visite nossa página de produto Atlas Vector Search. Para começar a usar o Vector Search, inscreva-se no Atlas ou faça log-in em sua conta.