In the previous blog post, “Time Series Data and MongoDB: Part 1 – An Introduction,” we introduced the concept of time-series data followed by some discovery questions you can use to help gather requirements for your time-series application. Answers to these questions help guide the schema and MongoDB database configuration needed to support a high-volume production application deployment. In this blog post we will focus on how two different schema designs can impact memory and disk utilization under read, write, update, and delete operations.
In the end of the analysis you may find that the best schema design for your application may be leveraging a combination of schema designs. By following the recommendations we lay out below, you will have a good starting point to develop the optimal schema design for your app, and appropriately size your environment.
Designing a time-series schema
Let’s start by saying that there is no one canonical schema design that fits all application scenarios. There will always be trade-offs to consider regardless of the schema you develop. Ideally you want the best balance of memory and disk utilization to yield the best read and write performance that satisfy your application requirements, and that enables you to support both data ingest and analysis of time-series data streams.
In this blog post we will look at various schema design configurations. First, storing one document per data sample, and then bucketing the data using one document per time-series time range and one document per fixed size. Storing more than one data sample per document is known as bucketing. This will be implemented at the application level and requires nothing to be configured specifically in MongoDB. With MongoDB’s flexible data model you can optimally bucket your data to yield the best performance and granularity for your application’s requirements.
This flexibility also allows your data model to adapt to new requirements over time – such as capturing data from new hardware sensors that were not part of the original application design. These new sensors provide different metadata and properties than the sensors you used in the original design. WIth all this flexibility you may think that MongoDB databases are the wild west, where anything goes and you can quickly end up with a database full of disorganized data. MongoDB provides as much control as you need via schema validation that allows you full control to enforce things like the presence of mandatory fields and range of acceptable values, to name a few.
To help illustrate how schema design and bucketing affects performance, consider the scenario where we want to store and analyze historical stock price data. Our sample stock price generator application creates sample data every second for a given number of stocks that it tracks. One second is the smallest time interval of data collected for each stock ticker in this example. If you would like to generate sample data in your own environment, the StockGen tool is available on GitHub. It is important to note that although the sample data in this document uses stock ticks as an example, you can apply these same design concepts to any time-series scenario like temperature and humidity readings from IoT sensors.
The StockGen tool used to generate sample data will generate the same data and store it in two different collections: StockDocPerSecond and StockDocPerMinute that each contain the following schemas:
Scenario 1: One document per data point
{
 "_id" : ObjectId("5b4690e047f49a04be523cbd"),
"p" : 56.56,
 "symbol" : "MDB",
 "d" : ISODate("2018-06-30T00:00:01Z")
},
{
 "_id" : ObjectId("5b4690e047f49a04be523cbe"),
"p" : 56.58,
 "symbol" : "MDB",
 "d" : ISODate("2018-06-30T00:00:02Z")
}
,...
Scenario 2: Time-based bucketing of one document per minute
{
"_id" : ObjectId("5b5279d1e303d394db6ea0f8"), 
"p" : {
"0" : 56.56,
"1" : 56.56,
"2" : 56.58,
…
"59" : 57.02
},
"symbol" : "MDB",
"d" : ISODate("2018-06-30T00:00:00Z")
},
{
"_id" : ObjectId("5b5279d1e303d394db6ea134"), 
"p" : {
 "0" : 69.47,
 "1" : 69.47,
 "2" : 68.46,
...
 "59" : 69.45
},
"symbol" : "TSLA",
"d" : ISODate("2018-06-30T00:01:00Z")
},...
Note that the field “p” contains a subdocument with the values for each second of the minute.
Schema design comparisons
Let’s compare and contrast the database metrics of storage size and memory impact based off of 4 weeks of data generated by the StockGen tool. Measuring these metrics is useful when assessing database performance.
Effects on Data Storage
In our application the smallest level of time granularity is a second. Storing one document per second as described in Scenario 1 is the most comfortable model concept for those coming from a relational database background. That is because we are using one document per data point, which is similar to a row per data point in a tabular schema. This design will produce the largest number of documents and collection size per unit of time as seen in Figures 3 and 4.
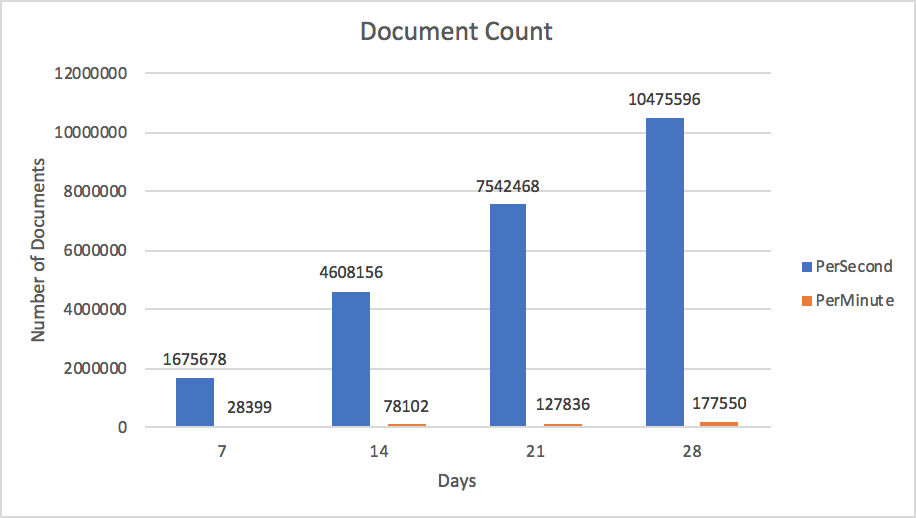
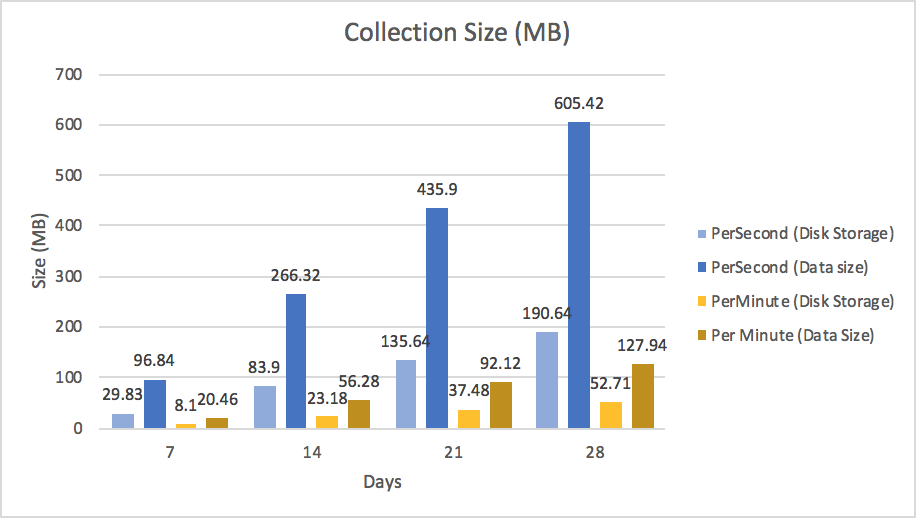
Figure 4 shows two sizes per collection. The first value in the series is the size of the collection that is stored on disk, while the second value is the size of the data in the database. These numbers are different because MongoDB’s WiredTiger storage engine supports compression of data at rest. Logically the PerSecond collection is 605MB, but on disk it is consuming around 190 MB of storage space.
Effects on memory utilization
A large number of documents will not only increase data storage consumption but increase index size as well. An index was created on each collection and covered the symbol and date fields. Unlike some key-value databases that position themselves as time-series databases, MongoDB provides secondary indexes giving you flexible access to your data and allowing you to optimize query performance of your application.
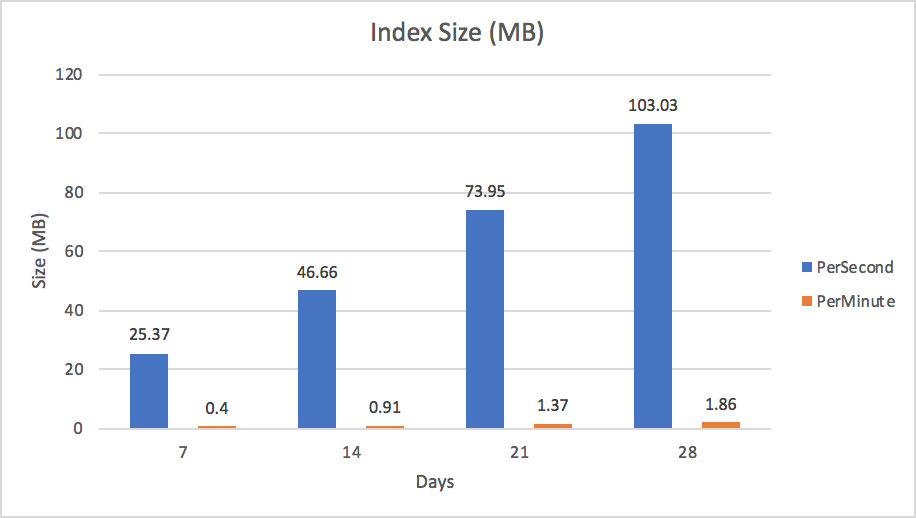
The size of the index defined in each of the two collections IS seen in Figure 5. Optimal performance of MongoDB happens when indexes and most recently used documents fit into the memory allocated by the WiredTiger cache (we call this the “working set”). In our example we generated data for just 5 stocks over the course of 4 weeks. Given this small test case our data already generated an index that is 103MB in size for the PerSecond scenario. Keep in mind that there are some optimizations such as index prefix compression that help reduce the memory footprint of an index. However, even with these kind of optimizations proper schema design is important to prevent runaway index sizes. Given the trajectory of growth, any changes to the application requirements, like tracking more than just 5 stocks or more than 4 weeks of prices in our sample scenario, will put much more pressure on memory and eventually require indexes to page out to disk. When this happens your performance will be degraded. To mitigate this situation, consider scaling horizontally.
Scale horizontally
As your data grows in size you may end up scaling horizontally when you reach the limits of the physical limits of the server hosting the primary mongod in your MongoDB replica set.
By horizontally scaling via MongoDB Sharding, performance can be improved since the indexes and data will be spread over multiple MongoDB nodes. Queries are no longer directed at a specific primary node. Rather they are processed by an intermediate service called a query router (mongos), which sends the query to the specific nodes that contain the data that satisfy the query. Note that this is completely transparent to the application – MongoDB handles all of the routing for you
Scenario 3: Size-based bucketing
The key takeaway when comparing the previous scenarios is that bucketing data has significant advantages. Time-based bucketing as described in scenario 2 buckets an entire minute's worth of data into a single document. In time-based applications such as IoT, sensor data may be generated at irregular intervals and some sensors may provide more data than others. In these scenarios, time-based bucketing may not be the optimal approach to schema design. An alternative strategy is size-based bucketing. With size-based bucketing we design our schema around one document per a certain number of emitted sensor events, or for the entire day, whichever comes first.
To see size-based bucketing in action, consider the scenario where you are storing sensor data and limiting the bucket size to 200 events per document, or a single day (whichever comes first). Note: The 200 limit is an arbitrary number and can be changed as needed, without application changes or schema migrations.
{
 _id: ObjectId(),
 deviceid: 1234,
 sensorid: 3,
 nsamples: 5,
 day: ISODate("2018-08-29"),
 first:1535530412,
 last: 1535530432,
 samples : [
 { val: 50, time: 1535530412},
 { val: 55, time : 1535530415},
 { val: 56, time: 1535530420},
 { val: 55, time : 1535530430},
 { val: 56, time: 1535530432}
 ]
}
An example size-based bucket is shown in figure 6. In this design, trying to limit inserts per document to an arbitrary number or a specific time period may seem difficult; however, it is easy to do using an upsert, as shown in the following code example:
sample = {val: 59, time: 1535530450}
day = ISODate("2018-08-29")
db.iot.updateOne({deviceid: 1234, sensorid: 3, nsamples: {$lt: 200}, day: day},
 {$push: {samples: sample},
 $min: {first: sample.time},
 $max: {last: sample.time},
 $inc: {nsamples: 1}, {upsert: true} )
As new sensor data comes in it is simply appended to the document until the number of samples hit 200, then a new document is created because of our upsert:true clause.
The optimal index in this scenario would be on {deviceid:1,sensorid:1,day:1,nsamples:1}. When we are updating data, the day is an exact match, and this is super efficient. When querying we can specify a date, or a date range on a single field which is also efficient as well as filtering by first and last using UNIX timestamps. Note that we are using integer values for times. These are really times stored as a UNIX timestamp and only take 32 bits of storage versus an ISODate which takes 64 bits. While not a significant query performance difference over ISODate, storing as UNIX timestamp may be significant if you plan on ending up with terabytes of ingested data and you do not need to store a granularity less than a second.
Bucketing data in a fixed size will yield very similar database storage and index improvements as seen when bucketing per time in scenario 2. It is one of the most efficient ways to store sparse IoT data in MongoDB.
What to do with old data
Should we store all data in perpetuity? Is data older than a certain time useful to your organization? How accessible should older data be? Can it be simply restored from a backup when you need it, or does it need to be online and accessible to users in real time as an active archive for historical analysis? As we covered in part 1 of this blog series, these are some of the questions that should be asked prior to going live.
There are multiple approaches to handling old data and depending on your specific requirements some may be more applicable than others. Choose the one that best fits your requirements.
Pre-aggregation
Does your application really need a single data point for every event generated years ago? In most cases the resource cost of keeping this granularity of data around outweighs the benefit of being able to query down to this level at any time. In most cases data can be pre-aggregated and stored for fast querying. In our stock example, we may want to only store the closing price for each day as a value. In most architectures, pre-aggregated values are stored in a separate collection since typically queries for historical data are different than real-time queries. Usually with historical data, queries are looking for trends over time versus individual real-time events. By storing this data in different collections you can increase performance by creating more efficient indexes as opposed to creating more indexes on top of real-time data.
Offline archival strategies
When data is archived, what is the SLA associated with retrieval of the data? Is restoring a backup of the data acceptable or does the data need to be online and ready to be queried at any given time? Answers to these questions will help drive your archive design. If you do not need real-time access to archival data you may want to consider backing up the data and removing it from the live database. Production databases can be backed up using MongoDB Ops Manager or if using the MongoDB Atlas service you can use a fully managed backup solution.
Removing documents using remove statement
Once data is copied to an archival repository via a database backup or an ETL process, data can be removed from a MongoDB collection via the remove statement as follows:
db.StockDocPerSecond.remove ( { "d" : { $lt: ISODate( "2018-03-01" ) } } )In this example all documents that have a date before March 1st, 2018 defined on the “d” field will be removed from the StockDocPerSecond collection.
You may need to set up an automation script to run every so often to clean out these records. Alternatively, you can avoid creating automation scripts in this scenario by defining a time to live (TTL) index.
Removing documents using a TTL Index
A TTL index is similar to a regular index except you define a time interval to automatically remove documents from a collection. In the case of our example, we could create a TTL index that automatically deletes data that is older than 1 week.
db.StockDocPerSecond.createIndex( { "d": 1 }, { expireAfterSeconds: 604800 } )Although TTL indexes are convenient, keep in mind that the check happens every minute or so and the interval cannot be configured. If you need more control so that deletions won’t happen during specific times of the day you may want to schedule a batch job that performs the deletion in lieu of using a TTL index.
Removing documents by dropping the collection
It is important to note that using the remove command or TTL indexes will cause high disk I/O. On a database that may be under high load already this may not be desirable. The most efficient and fastest way to remove records from the live database is to drop the collection. If you can design your application such that each collection represents a block of time, \ when you need to archive or remove data all you need to do is drop the collection. This may require some smarts within your application code to know which collections should be queried, but the benefit may outweigh this change. When you issue a remove, MongoDB also has to remove data from all affected indexes as well and this could take a while depending on the size of data and indexes.
Online archival strategies
If archival data still needs to be accessed in real time, consider how frequently these queries occur and if storing only pre-aggregated results can be sufficient.
Sharding archival data
One strategy for archiving data and keeping the data accessible real-time is by using zoned sharding to partition the data. Sharding not only helps with horizontally scaling the data out across multiple nodes, but you can tag shard ranges so partitions of data are pinned to specific shards. A cost saving measure could be to have the archival data live on shards running lower cost disks and periodically adjusting the time ranges defined in the shards themselves. These ranges would cause the balancer to automatically move the data between these storage layers, providing you with tiered, multi-temperature storage. Review our tutorial for creating tiered storage patterns with zoned sharding for more information.
Accessing archived data via queryable backups
If your archive data is not accessed that frequently and the query performance does not need to meet any strict latency SLAs, consider backing the data up and using the Queryable Backups feature of MongoDB Atlas or MongoDB OpsManager. Queryable Backups allow you to connect to your backup and issue read-only commands to the backup itself, without having to first restore the backup.
Querying data from the data lake
MongoDB is an inexpensive solution not only for long term archival but for your data lake as well. Companies who have made investments in technologies like Apache Spark can leverage the MongoDB Spark Connector. This connector materializes MongoDB data as DataFrames and Datasets for use with Spark and machine learning, graph, streaming, and SQL APIs.
Key Takeaways
Once an application is live in production and is multiple terabytes in size, any major change can be very expensive from a resource standpoint. Consider the scenario where you have 6 TB of IoT sensor data and are accumulating new data at a rate of 50,000 inserts per second. Performance of reads is starting to become an issue and you realize that you have not properly scaled out the database. Unless you are willing to take application downtime, a change of schema in this configuration – e.g., moving from raw data storage to bucketed storage – may require building out shims, temporary staging areas and all sorts of transient solutions to move the application to the new schema. The moral of the story is to plan for growth and properly design the best time-series schema that fits your application’s SLAs and requirements.
This article analyzed two different schema designs for storing time-series data from stock prices. Is the schema that won in the end for this stock price database the one that will be the best in your scenario? Maybe. Due to the nature of time-series data and the typical rapid ingestion of data the answer may in fact be leveraging a combination of collections that target a read or write heavy use case. The good news is that with MongoDB’s flexible schema, it is easy to make changes. In fact you can run two different versions of the app writing two different schemas to the same collection. However, don’t wait until your query performance starts suffering to figure out an optimal design as migrating TBs of existing documents into a new schema can take time and resources, and delay future releases of your application. You should undertake real world testing before commiting on a final design. Quoting a famous proverb, “Measure twice and cut once.”
In the next blog post, “Querying, Analyzing, and Presenting Time-Series Data with MongoDB,” we will look at how to effectively get value from the time-series data stored in MongoDB.
Key Tips:
- The MMAPV1 storage engine is deprecated, so use the default WiredTiger storage engine. Note that if you read older schema design best practices from a few years ago, they were often built on the older MMAPV1 technology.
- Understand what the data access requirements are from your time-series application.
- Schema design impacts resources. “Measure twice and cut once” with respect to schema design and indexes.
- Test schema patterns with real data and a real application if possible.
- Bucketing data reduces index size and thus massively reduces hardware requirements.
- Time-series applications traditionally capture very large amounts of data, so only create indexes where they will be useful to the app’s query patterns.
- Consider more than one collection: one focused on write heavy inserts and recent data queries and another collection with bucketed data focused on historical queries on pre-aggregated data.
- When the size of your indexes exceeds the amount of memory on the server hosting MongoDB, consider horizontally scaling out to spread the index and load over multiple servers.
- Determine at what point data expires, and what action to take, such as archival or deletion.