Introduction
Determining the best database for a modern application to be deployed across multiple data centers requires careful evaluation to accommodate a variety of complex application requirements. The database will be responsible for processing reads and writes in multiple geographies, replicating changes among them, and providing the highest possible availability, consistency, and durability guarantees. But not all technology choices are equal. For example, one database technology might provide a higher guarantee of availability while providing lower data consistency and durability guarantees than another technology. The tradeoffs made by an individual database technology will affect the behavior of the application upon which it is built.
Unfortunately, there is limited understanding among many application architects as to the specific tradeoffs made by various modern databases. The popular belief appears to be that if an application must accept writes concurrently in multiple data centers, then it needs to use a multi-master database – where multiple masters are responsible for a single copy or partition of the data. This is a misconception and it is compounded by a limited understanding of the (potentially negative) implications this choice has on application behavior.
To provide some clarity on this topic, this post will begin by describing the database capabilities required by modern multi-data center applications. Next, it describes the categories of database architectures used to realize these requirements and summarize the pros and cons of each. Finally, it will look at MongoDB specifically and describe how it fits into these categories. It will list some of the specific capabilities and design choices offered by MongoDB that make it suited for global application deployments.
Active-Active Requirements
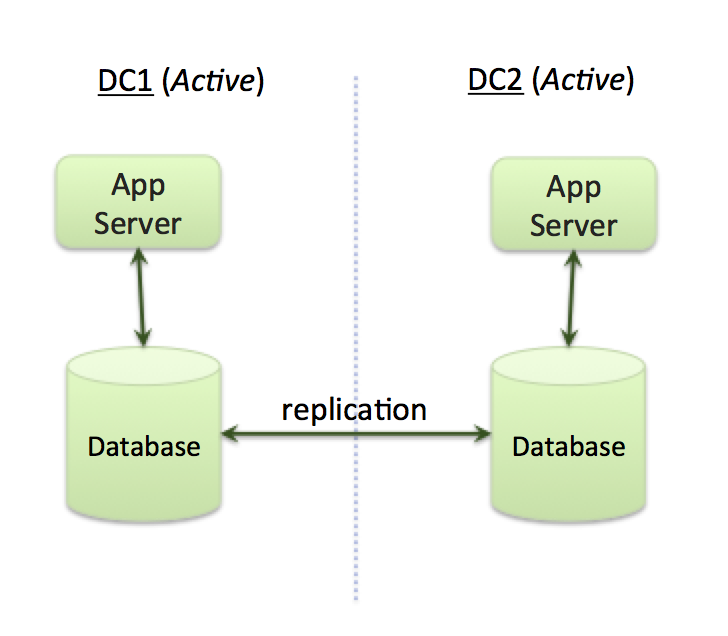
When organizations consider deploying applications across multiple data centers (or cloud regions) they typically want to use an active-active architecture. At a high-level, this means deploying an application across multiple data centers where application servers in all data centers are simultaneously processing requests (Figure 1). This architecture aims to achieve a number of objectives:
- Serve a globally distributed audience by providing local processing (low latencies)
- Maintain always-on availability, even in the face of complete regional outages
- Provide the best utilization of platform resources by allowing server resources in multiple data centers to be used in parallel to process application requests.
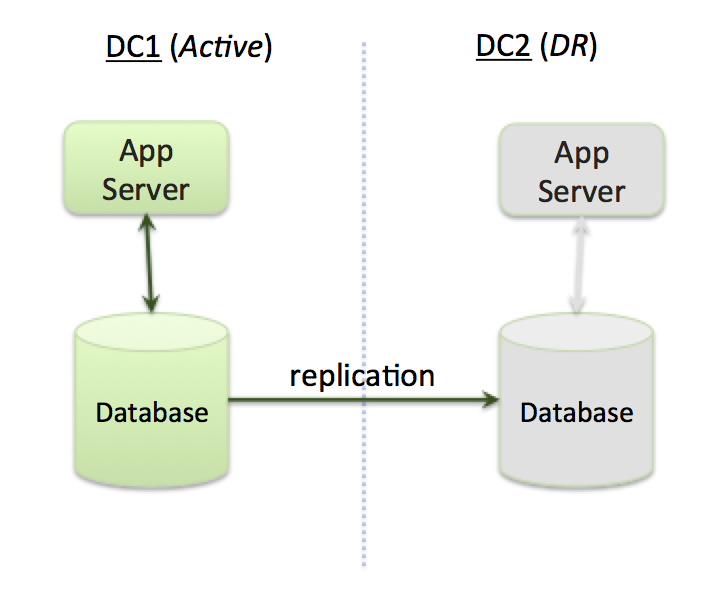
An alternative to an active-active architecture is an active-disaster recovery (also known as active-passive) architecture consisting of a primary data center (region) and one or more disaster recovery (DR) regions (Figure 2). Under normal operating conditions, the primary data center processes requests and the DR center is idle. The DR site only starts processing requests (becomes active), if the primary data center fails. (Under normal situations, data is replicated from primary to DR sites, so that the the DR sites can take over if the primary data center fails).
The definition of an active-active architecture is not universally agreed upon. Often, it is also used to describe application architectures that are similar to the active-DR architecture described above, with the distinction being that the failover from primary to DR site is fast (typically a few seconds) and automatic (no human intervention required). In this interpretation, an active-active architecture implies that application downtime is minimal (near zero).
A common misconception is that an active-active application architecture requires a multi-master database. This is not only false, but using a multi-master database means relaxing requirements that most data owners hold dear: consistency and data durability. Consistency ensures that reads reflect the results of previous writes. Data durability ensures that committed writes will persist permanently: no data is lost due to the resolution of conflicting writes or node failures. Both these database requirements are essential for building applications that behave in the predictable and deterministic way users expect.
To address the multi-master misconception, let’s start by looking at the various database architectures that could be used to achieve an active-active application, and the pros and cons of each. Once we have done this, we will drill into MongoDB’s architecture and look at how it can be used to deploy an Active-Active application architecture.
Database Requirements for Active-Active Applications
When designing an active-active application architecture, the database tier must meet four architectural requirements (in addition to standard database functionality: powerful query language with rich secondary indexes, low latency access to data, native drivers, comprehensive operational tooling, etc.):
- Performance - low latency reads and writes. It typically means processing reads and writes on nodes in a data center local to the application.
- Data durability - Implemented by replicating writes to multiple nodes so that data persists when system failures occur.
- Consistency - Ensuring that readers see the results of previous writes, readers to various nodes in different regions get the same results, etc.
- Availability - The database must continue to operate when nodes, data centers, or network connections fail. In addition, the recovery from these failures should be as short as possible. A typical requirement is a few seconds.
Due to the laws of physics, e.g., the speed of light, it is not possible for any database to completely satisfy all these requirements at the same time, so the important consideration for any engineering team building an application is to understand the tradeoffs made by each database and selecting the one that provides for the application’s most critical requirements.
Let’s look at each of these requirements in more detail.
Performance
For performance reasons, it is necessary for application servers in a data center to be able to perform reads and writes to database nodes in the same data center, as most applications require millisecond (a few to tens) response times from databases. Communication among nodes across multiple data centers can make it difficult to achieve performance SLAs. If local reads and write are not possible, then the latency associated with sending queries to remote servers significantly impacts application response time. For example, customers in Australia would not expect to have a far worse user experience than customers in the eastern US where the e-commerce vendors primary data center is located. In addition, the lack of network bandwidth between data centers can also be a limiting factor.
Data Durability
Replication is a critical feature in a distributed database. The database must ensure that writes made to one node are replicated to the other nodes that maintain replicas of the same record, even if these nodes are in different physical locations. The replication speed and data durability guarantees provided will vary among databases, and are influenced by:
- The set of nodes that accept writes for a given record
- The situations when data loss can occur
- Whether conflicting writes (two different writes occurring to the same record in different data centers at about the same time) are allowed, and how they are resolved when they occur
Consistency
The consistency guarantees of a distributed database vary significantly. This variance depends upon a number of factors, including whether indexes are updated atomically with data, the replication mechanisms used, how much information individual nodes have about the status of corresponding records on other nodes, etc.
The weakest level of consistency offered by most distributed databases is eventual consistency. It simply guarantees that, eventually, if all writes are stopped, the value for a record across all nodes in the database will eventually coalesce to the same value. It provides few guarantees about whether an individual application process will read the results of its write, or if value read is the latest value for a record.
The strongest consistency guarantee that can be provided by distributed databases without severe impact to performance is causal consistency. As described by Wikipedia, causal consistency provides the following guarantees:
- Read Your Writes: this means that preceding write operations are indicated and reflected by the following read operations.
- Monotonic Reads: this implies that an up-to-date increasing set of write operations is guaranteed to be indicated by later read operations.
- Writes Follow Reads: this provides an assurance that write operations follow and come after reads by which they are influenced.
- Monotonic Writes: this guarantees that write operations must go after other writes that reasonably should precede them.
Most distributed databases will provide consistency guarantees between eventual and causal consistency. The closer to causal consistency the more an application will behave as users expect, e.g.,queries will return the values of previous writes, data won’t appear to be lost, and data values will not change in non-deterministic ways.
Availability
The availability of a database describes how well the database survives the loss of a node, a data center, or network communication. The degree to which the database continues to process reads and writes in the event of different types of failures and the amount of time required to recover from failures will determine its availability. Some architectures will allow reads and writes to nodes isolated from the rest of the database cluster by a network partition, and thus provide a high level of availability. Also, different databases will vary in the amount of time it takes to detect and recover from failures, with some requiring manual operator intervention to restore a healthy database cluster.
Distributed Database Architectures
There are three broad categories of database architectures deployed to meet these requirements:
- Distributed transactions using two-phase commit
- Multi-Master, sometimes also called “masterless”
- Partitioned (sharded) database with multiple primaries each responsible for a unique partition of the data
Let’s look at each of these options in more detail, as well as the pros and cons of each.
Distributed Transactions with Two-Phase Commit
A distributed transaction approach updates all nodes containing a record as part of a single transaction, instead of having writes being made to one node and then (asynchronously) replicated to other nodes. The transaction guarantees that all nodes will receive the update or the transaction will fail and all nodes will revert back to the previous state if there is any type of failure.
A common protocol for implementing this functionality is called a two-phase commit. The two-phase commit protocol ensures durability and multi-node consistency, but it sacrifices performance. The two-phase commit protocol requires two-phases of communication among all the nodes involved in the transaction with requests and acknowledgments sent at each phase of the operation to ensure every node commits the same write at the same time. When database nodes are distributed across multiple data centers this often pushes query latency from the millisecond range to the multi-second range. Most applications, especially those where the clients are users (mobile devices, web browsers, client applications, etc.) find this level of response time unacceptable.
Multi-Master
A multi-master database is a distributed database that allows a record to be updated in one of many possible clustered nodes. (Writes are usually replicated so records exist on multiple nodes and in multiple data centers.) On the surface, a multi-master database seems like the ideal platform to realize an active-active architecture. It enables each application server to read and write to a local copy of the data with no restrictions. It has serious limitations, however, when it comes to data consistency.
The challenge is that two (or more) copies of the same record may be updated simultaneously by different sessions in different locations. This leads to two different versions of the same record and the database, or sometimes the application itself, must perform conflict resolution to resolve this inconsistency. Most often, a conflict resolution strategy, such as most recent update wins or the record with the larger number of modifications wins, is used since performance would be significantly impacted if some other more sophisticated resolution strategy was applied. This also means that readers in different data centers may see a different and conflicting value for the same record for the time between the writes being applied and the completion of the conflict resolution mechanism.
For example, let’s assume we are using a multi-master database as the persistence store for a shopping cart application and this application is deployed in two data centers: East and West. At roughly the same time, a user in San Francisco adds an item to his shopping cart (a flashlight) while an inventory management process in the East data center invalidates a different shopping cart item (game console) for that same user in response to a supplier notification that the release date had been delayed (See times 0 to 1 in Figure 3).
At time 1, the shopping cart records in the two data centers are different. The database will use its replication and conflict resolution mechanisms to resolve this inconsistency and eventually one of the two versions of the shopping cart (See time 2 in Figure 3) will be selected. Using the conflict resolution heuristics most often applied by multi-master databases (last update wins or most updated wins), it is impossible for the user or application to predict which version will be selected. In either case, data is lost and unexpected behavior occurs. If the East version is selected, then the user’s selection of a flashlight is lost and if the West version is selected, the the game console is still in the cart. Either way, information is lost. Finally, any other process inspecting the shopping cart between times 1 and 2 is going to see non-deterministic behavior as well. For example, a background process that selects the fulfillment warehouse and updates the cart shipping costs would produce results that conflict with the eventual contents of the cart. If the process is running in the West and alternative 1 becomes reality, it would compute the shipping costs for all three items, even though the cart may soon have just one item, the book.
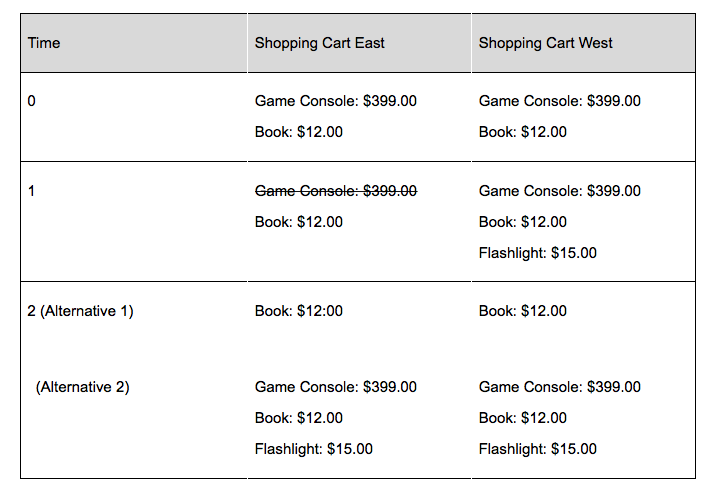
The set of uses cases for multi-master databases is limited to the capture of non-mission-critical data, like log data, where the occasional lost record is acceptable. Most use cases cannot tolerate the combination of data loss resulting from throwing away one version of a record during conflict resolution, and inconsistent reads that occur during this process.
Partitioned (Sharded) Database
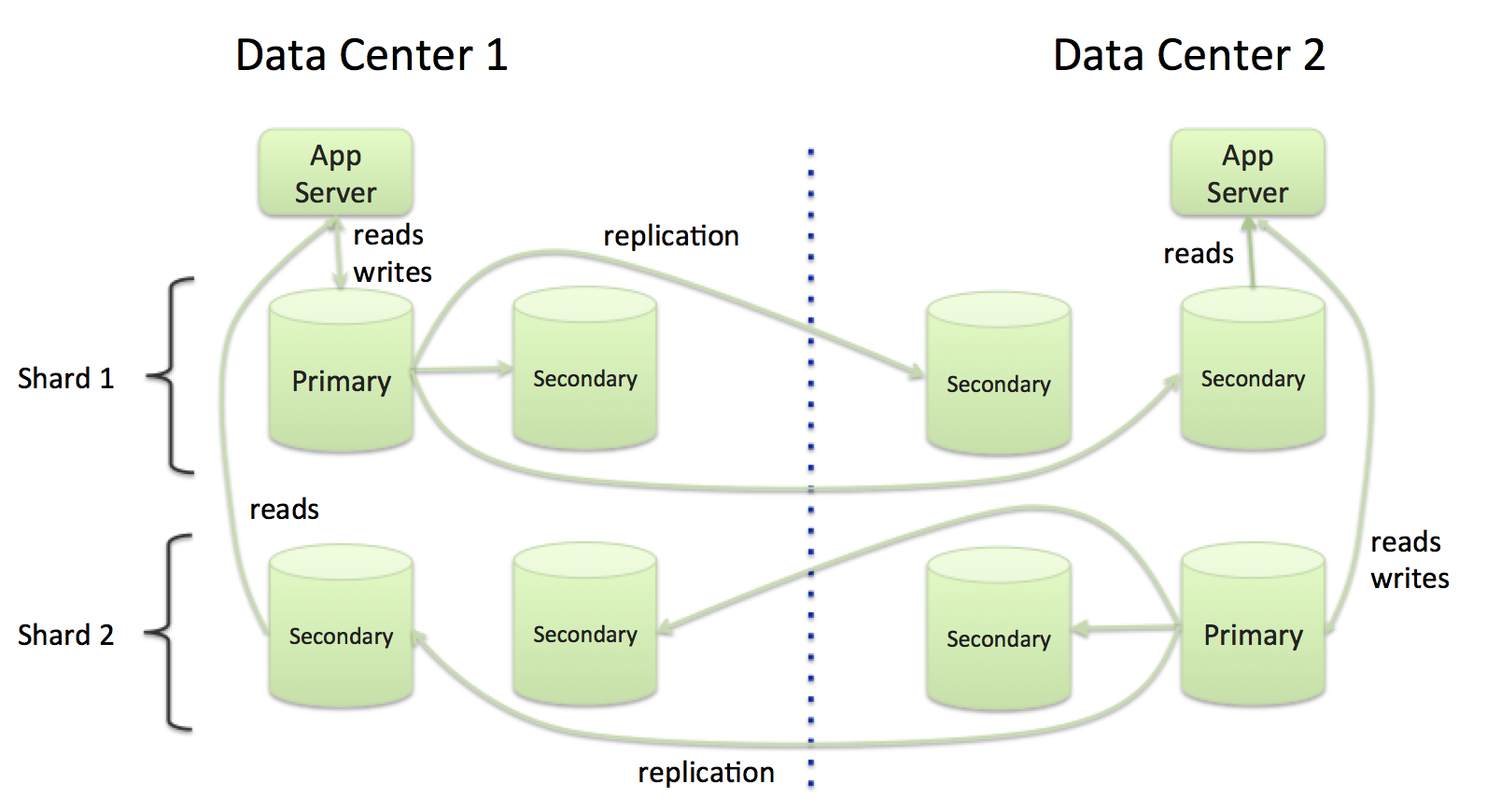
A partitioned database divides the database into partitions, called shards. Each shard is implemented by a set of servers each of which contains a complete copy of the partition’s data. What is key here is that each shard maintains exclusive control of its partition of the data. At any given time, for each shard, one server acts as the primary and the other servers act as secondary replicas. Reads and writes are issued to the primary copy of the data. If the primary server fails for any reason (e.g., hardware failure, network partition) one of the secondary servers is automatically elected to primary.
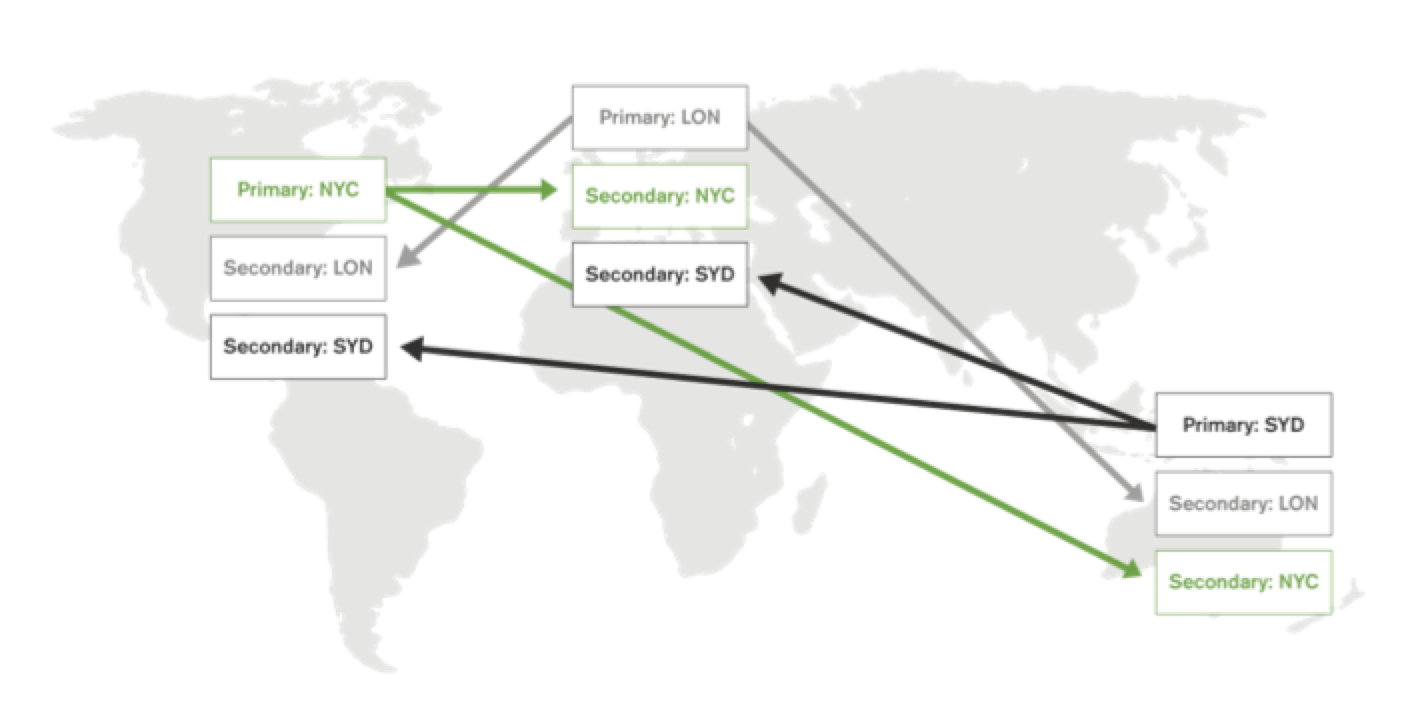
Each record in the database belongs to a specific partition, and is managed by exactly one shard, ensuring that it can only be written to the shard’s primary. The mapping of records to shards and the existence of exactly one primary per shard ensures consistency. Since the cluster contains multiple shards, and hence multiple primaries (multiple masters), these primaries may be distributed among the data centers to ensure that writes can occur locally in each datacenter (Figure 4).
A sharded database can be used to implement an active-active application architecture by deploying at least as many shards as data centers and placing the primaries for the shards so that each data center has at least one primary (Figure 5). In addition, the shards are configured so that each shard has at least one replica (copy of the data) in each of the datacenters. For example, the diagram in Figure 5 depicts a database architecture distributed across three datacenters: New York (NYC), London (LON), and Sydney (SYD). The cluster has three shards where each shard has three replicas.
- The NYC shard has a primary in New York and secondaries in London and Sydney
- The LON shard has a primary in London and secondaries in New York and Sydney
- The SYD shard has a primary in Sydney and secondaries in New York and London
In this way, each data center has secondaries from all the shards so the local app servers can read the entire data set and a primary for one shard so that writes can be made locally as well.
The sharded database meets most of the consistency and performance requirements for a majority of use cases. Performance is great because reads and writes happen to local servers. When reading from the primaries, consistency is assured since each record is assigned to exactly one primary. This option requires architecting the application so that users/queries are routed to the data center that manages the data (contains the primary) for the query. Often this is done via geography. For example, if we have two data centers in the United States (New Jersey and Oregon), we might shard the data set by geography (East and West) and route traffic for East Coast users to the New Jersey data center, which contains the primary for the Eastern shard, and route traffic for West Coast users to the Oregon data center, which contains the primary for the Western shard.
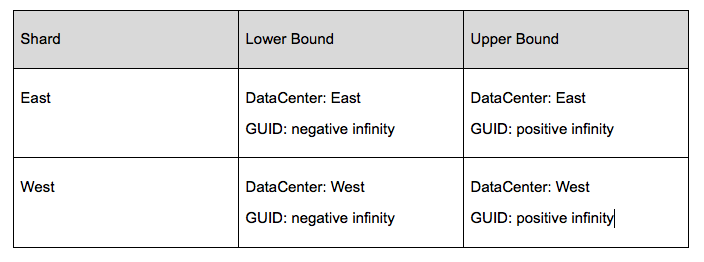
Let’s revisit the shopping cart example using a sharded database. Again, let’s assume two data centers: East and West. For this implementation, we would shard (partition) the shopping carts by their shopping card ID plus a data center field identifying the data center in which the shopping cart was created. The partitioning (Figure 6) would ensure that all shopping carts with a DataCenter field value of “East” would be managed by the shard with the primary in the East data center. The other shard would manage carts with the value of “West”. In addition, we would need two instances of the inventory management service, one deployed in each data center, with responsibility for updating the carts owned by the local data center.
This design assumes that there is some external process routing traffic to the correct data center. When a new cart is created, the user’s session will be routed to the geographically closest data center and then assigned a DataCenter value for that data center. For an existing cart, the router can use the cart’s DataCenter field to identify the correct data center.
From this example, we can see that the sharded database gives us all the benefits of a multi-master database without the complexities that come from data inconsistency. Applications servers can read and write from their local primary, but because each cart is owned by a single primary, no inconsistencies can occur. In contrast, multi-master solutions have the potential for data loss and inconsistent reads.
Database Architecture Comparison
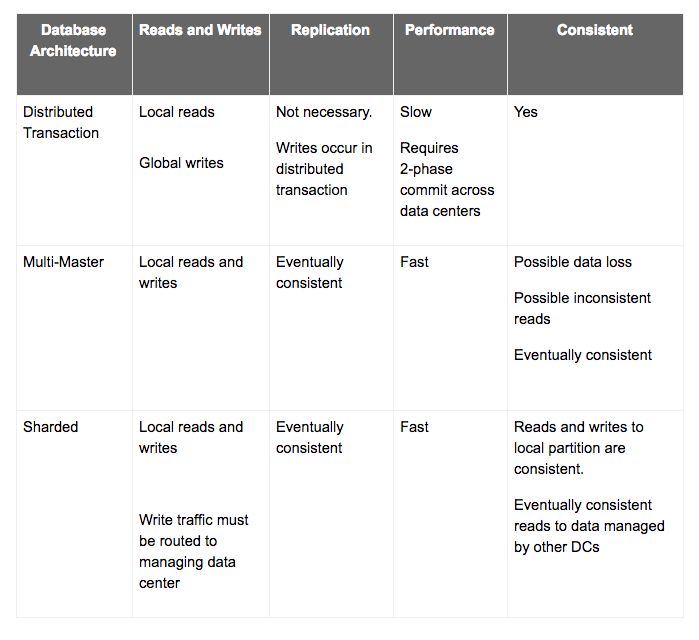
The pros and cons of how well each database architecture meets active-active application requirements is provided in Figure 7. In choosing between multi-master and sharded databases, the decision comes down to whether or not the application can tolerate potentially inconsistent reads and data loss. If the answer is yes, then a multi-master database might be slightly easier to deploy. If the answer is no, then a sharded database is the best option. Since inconsistency and data loss are not acceptable for most applications, a sharded database is usually the best option.
MongoDB Active-Active Applications
MongoDB is an example of a sharded database architecture. In MongoDB, the construct of a primary server and set of secondary servers is called a replica set. Replica sets provide high availability for each shard and a mechanism, called Zone Sharding, is used to configure the set of data managed by each shard. Zone sharding makes it possible to implement the geographical partitioning described in the previous section. The details of how to accomplish this are described in the “MongoDB Multi-Data Center Deployments” white paper and Zone Sharding documentation, but MongoDB operates as described in the “Partitioned (Sharded) Database” section.
Numerous organizations use MongoDB to implement active-active application architectures. For example:
- Ebay has codified the use of zone sharding to enable local reads and writes as one of its standard architecture patterns.
- YouGov deploys MongoDB for their flagship survey system, called Gryphon, in a “write local, read global” pattern that facilitates active-active multi data center deployments spanning data centers in North America and Europe.
- Ogilvy and Maher uses MongoDB as the persistence store for its core auditing application. Their sharded cluster spans three data centers in North America and Europe with active data centers in North American and mainland Europe and a DR data center in London. This architecture minimizes write latency and also supports local reads for centralized analytics and reporting against the entire data set.
In addition to the standard sharded database functionality, MongoDB provides fine grain controls for write durability and read consistency that make it ideal for multi-data center deployments. For writes, a write concern can be specified to control write durability. The write concern enables the application to specify the number of replica set members that must apply the write before MongoDB acknowledges the write to the application. By providing a write concern, an application can be sure that when MongoDB acknowledges the write, the servers in one or more remote data centers have also applied the write. This ensures that database changes will not be lost in the event of node or a data center failure.
In addition, MongoDB addresses one of the potential downsides of a sharded database: less than 100% write availability. Since there is only one primary for each record, if that primary fails, then there is a period of time when writes to the partition cannot occur. MongoDB combines extremely fast failover times with retryable writes. With retryable writes, MongoDB provides automated support for retrying writes that have failed due to transient system errors such as network failures or primary elections, , therefore significantly simplifying application code.
The speed of MongoDB’s automated failover is another distinguishing feature that makes MongoDB ideally suited for multi-data center deployments. MongoDB is able to failover in 2-5 seconds (depending upon configuration and network reliability), when a node or data center fails or network split occurs. (Note, secondary reads can continue during the failover period.) After a failure occurs, the remaining replica set members will elect a new primary and MongoDB’s driver, upon which most applications are built, will automatically identify this new primary. The recovery process is automatic and writes continue after the failover process completes.
For reads, MongoDB provides two capabilities for specifying the desired level of consistency. First, when reading from secondaries, an application can specify a maximum staleness value (maxStalenessSeconds). This ensures that the secondary’s replication lag from the primary cannot be greater than the specified duration, and thus, guarantees the currentness of the data being returned by the secondary. In addition, a read can also be associated with a ReadConcern to control the consistency of the data returned by the query. For example, a ReadConcern of majority tells MongoDB to only return data that has been replicated to a majority of nodes in the replica set. This ensures that the query is only reading data that will not be lost due to a node or data center failure, and gives the application a consistent view of the data over time.
MongoDB 3.6 also introduced causal consistency – guaranteeing that every read operation within a client session will always see the previous write operation, regardless of which replica is serving the request. By enforcing strict, causal ordering of operations within a session, causal consistency ensures every read is always logically consistent, enabling monotonic reads from a distributed system – guarantees that cannot be met by most multi-node databases. Causal consistency allows developers to maintain the benefits of strict data consistency enforced by legacy single node relational databases, while modernizing their infrastructure to take advantage of the scalability and availability benefits of modern distributed data platforms.
Conclusion
In this post we have shown that sharded databases provide the best support for the replication, performance, consistency, and local-write, local-read requirements of active-active applications. The performance of distributed transaction databases is too slow and multi-master databases do not provide the required consistency guarantees. In addition, MongoDB is especially suited for multi-data center deployments due to its distributed architecture, fast failover and ability for applications to specify desired consistency and durability guarantees through Read and Write Concerns.
|
|