20 billion documents, 15TB of data scaled across a MongoDB cluster in the cloud. New apps each adding 1 billion+ data points per month
With mobile now accounting for more than 90% of all time spent online in some countries, delivering rich app experiences is essential. Appsee is a new generation of mobile analytics company providing business owners with deep insights into user behavior, enabling them to increase engagement, conversion, and monetization. Customers include eBay, AVIS, Virgin, Samsung, Argos, Upwork, and many more. Appsee is also featured in Google’s Fabric platform. Appsee relies on MongoDB to ingest the firehose of time-series session data collected from its customers’ mobile apps, and then makes sense of it all.
I met with Yoni Douek, CTO and co-founder of Appsee, to learn more.
Can you start by telling us a little bit about your company?
Appsee is a real-time mobile app analytics platform that provides what we call “qualitative analytics”. Our goal is to help companies understand exactly how users are using their app with a very deep set of tools, so that they can improve their app. Traditional analytics help you see numbers – we also provide reasons behind these numbers.
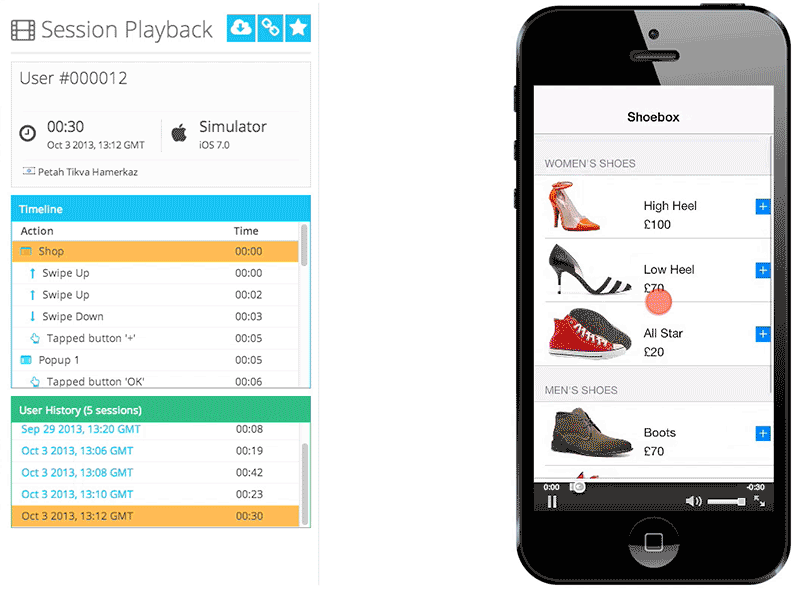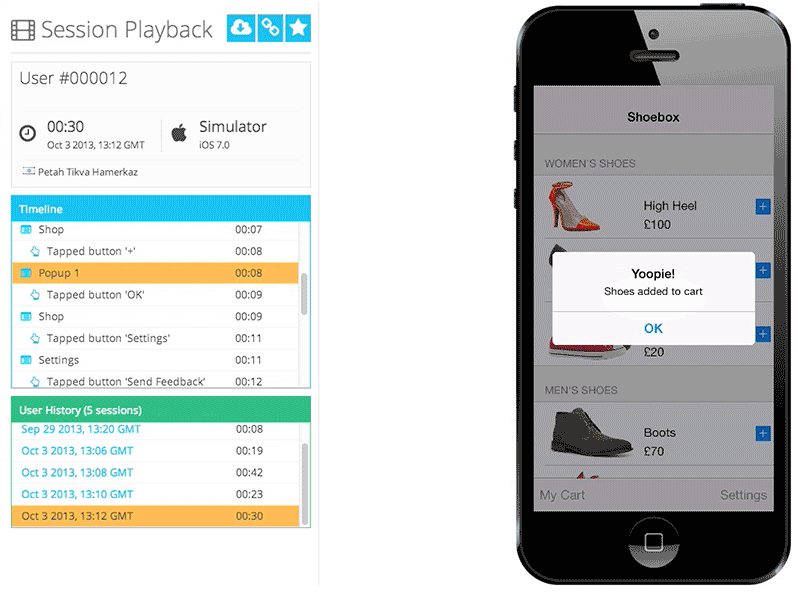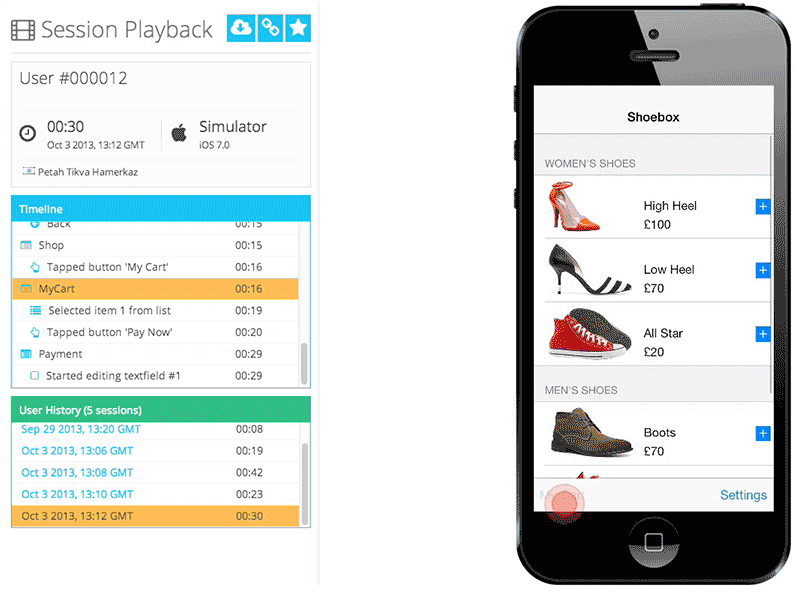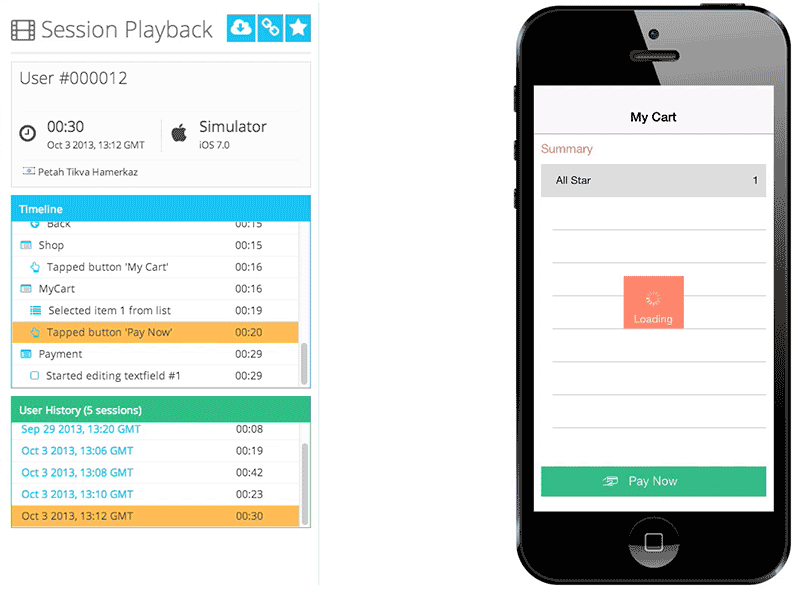
One of Appsee's key qualitative tools is session recordings and replay, which enable our customers to obtain the most accurate and complete picture of each user's in-app experience. We also offer touch heatmaps, which highlight exactly where users are interacting with each screen, and where users are encountering any usability issues. Our platform also provides real-time analytics, user flows, UX insights, crash statistics, and many more insights that help companies in optimizing their app.
Please describe how you’re using MongoDB
Our service has two distinct data storage requirements, both of which are powered by MongoDB.
Session database: storing activity from each user as they interact with the mobile application. Session data is captured as a time-series data stream into MongoDB, including which screens they visit, for how long, what they are tapping or swiping, crashes, and so on. This raw session data is modeled in a single document, typically around 6KB in size. Complete user sessions can be reconstructed from this single MongoDB document, allowing mobile app professionals to watch the session as a video, and to optimize their app experiences.
Real-time mobile analytics database: session data is aggregated and stored in MongoDB to provide in-depth analysis of user behavior. Through 50+ charts and graphs, app owners can track a range of critical metrics including total installs, app version adoption, conversion funnels and cohorts, user flows, crash analytics, average session times, user retention rates, and more.
We make extensive use of MongoDB’s aggregation pipeline, relying on it for matching, grouping, projecting, and sorting of raw session data, combined with the various accumulator and array manipulation expressions to transform and analyze data. MongoDB’s secondary indexes allow us to efficiently access data by any dimension and query pattern. We typically enforce three or four secondary indexes on each collection.
Why did you select MongoDB?
When we began developing the Appsee service, we had a long list of requirements for the database:
- Elastic scalability, with almost infinite capacity for user and data growth
- High insert performance required for time-series data, coupled with low latency read performance for analytics
- Reliable data storage so we would never lose a single user session
- Flexible data model so we could persist highly complex, rapidly changing data generated by new generations of mobile apps
- Developer ease-of-use, to allow us to maximize the productivity of our team, and shorten time to market. This was especially important in the early days of the company, as at the time, we only had two developers
- Support for rich, in-database analytics so we could deliver real-insights to app owners, without having to move data into dedicated analytics nodes or data warehousing infrastructure.
As we came from a relational database background, we initially thought about MySQL. But the restrictive data model imposed by its relational schema, and inability to scale writes beyond a single node made us realize it wouldn’t meet our needs.
We reviewed a whole host of NoSQL alternatives, and it soon became clear that the best multi-purpose database that met all of our requirements was MongoDB. Its ability to handle high velocity streams of time series data, and analyze it in place was key. And the database was backed by a vibrant and helpful community, with mature documentation that would reduce our learning curve.
Can you tell us what your MongoDB deployment looks like?
We currently run a 5-shard MongoDB cluster, with a 3-node replica set provisioned for each shard, providing self-healing recovery. We run on top of AWS, with CPU-optimized Linux-based instances.
We are on MongoDB 3.2, using the Python and C# drivers, with plans to upgrade to the latest MongoDB 3.4 release later in the year. This will help us take advantage of parallel chunk migrations for faster cluster balancing as we continue to elastically scale-out.
Can you share how MongoDB is performing for you?
MongoDB is currently storing 20 billion documents, amounting to 15TB of data, which we expect to double over the next 12 months. The cluster is currently handling around 50,000 operations per second, with a 50:50 split between reads and inserts. Through our load testing, we know we can support 2x growth on the same hardware footprint.
Can you share best practices for scaling?
My top recommendation would be to shard before you actually need to – this will ensure you have plenty of capacity to respond to sudden growth requirements when you need to. Don’t leave sharding until you are close to maximum utilization on your current setup.
To put our scale into context, every app that goes live with Appsee can send us 1 billion+ data points per month as soon it launches. Every few weeks we run a load test that simulates 2x of the data we are currently processing. From those tests, we adapt our shards, collections and servers to be able to handle that doubling in load.
How do you monitor your cluster?
We are using Cloud Manager to monitor MongoDB, and our own monitoring system based on Grafana, Telegraf, and Kapacitor for the rest of the application stack.

How are you measuring the impact of MongoDB on your business?
Speed to market, application functionality, customer experience, and platform efficiency.
- We can build new features and functionality faster with MongoDB. When we hire new developers, MongoDB University training and documentation gets them productive within days.
- MongoDB simplifies our data architecture. It is a truly multi-purpose platform – supporting high speed data ingest of time-series data, coupled the ability to perform rich analytics against that data, without having to use multiple technologies.
- Our service is able to sustain high uptime. Using MongoDB’s distributed, self-healing replica set architecture, we deploy across AWS availability zones and regions for fault tolerance and zero downtime upgrades.
- Each generation of MongoDB brings greater platform efficiency. For example, upgrading to the WiredTiger storage engine cut our storage consumption by 30% overnight.
MongoDB development is open and collaborative – giving us the opportunity to help shape the product. Through the MongoDB Jira project, we engage directly with the MongoDB engineering team, filing feature requests and bug reports. It is as though MongoDB engineers are an extension of our team!
Yoni, thanks for taking the time to share your experience with the company
To learn more about best practices for deploying and running MongoDB on AWS, download our guide.