We are excited to announce a robust set of vector quantization capabilities in MongoDB Atlas Vector Search. These capabilities will reduce vector sizes while preserving performance, enabling developers to build powerful semantic search and generative AI applications with more scale—and at a lower cost. In addition, unlike relational or niche vector databases, MongoDB’s flexible document model—coupled with quantized vectors—allows for greater agility in testing and deploying different embedding models quickly and easily.
Support for scalar quantized vector ingestion is now generally available, and will be followed by several new releases in the coming weeks. Read on to learn how vector quantization works and visit our documentation to get started!
The challenges of large-scale vector applications
While the use of vectors has opened up a range of new possibilities, such as content summarization and sentiment analysis, natural language chatbots, and image generation, unlocking insights within unstructured data can require storing and searching through billions of vectors—which can quickly become infeasible.
Vectors are effectively arrays of floating-point numbers representing unstructured information in a way that computers can understand (ranging from a few hundred to billions of arrays), and as the number of vectors increases, so does the index size required to search over them. As a result, large-scale vector-based applications using full-fidelity vectors often have high processing costs and slow query times, hindering their scalability and performance.
Vector quantization for cost-effectiveness, scalability, and performance
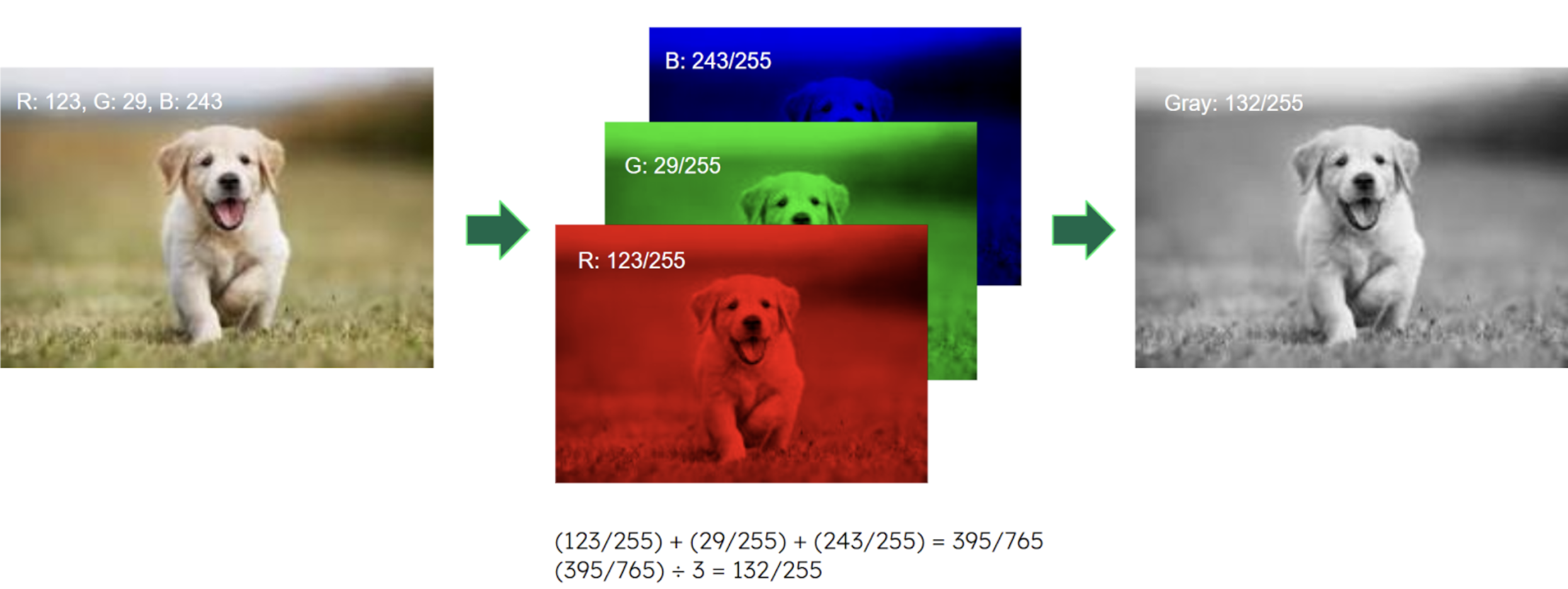
Vector quantization, a technique that compresses vectors while preserving their semantic similarity, offers a solution to this challenge. Imagine converting a full-color image into grayscale to reduce storage space on a computer. This involves simplifying each pixel's color information by grouping similar colors into primary color channels or "quantization bins," and then representing each pixel with a single value from its bin. The binned values are then used to create a new grayscale image with smaller size but retaining most original details, as shown in Figure 1.
Vector quantization works similarly, by shrinking full-fidelity vectors into fewer bits to significantly reduce memory and storage costs without compromising the important details. Maintaining this balance is critical, as search and AI applications need to deliver relevant insights to be useful.
Two effective quantization methods are scalar (converting a float point into an integer) and binary (converting a float point into a single bit of 0 or 1). Current and upcoming quantization capabilities will empower developers to maximize the potential of Atlas Vector Search.
The most impactful benefit of vector quantization is increased scalability and cost savings through reduced computing resources and efficient processing of vectors. And when combined with Search Nodes—MongoDB’s dedicated infrastructure for independent scalability through workload isolation and memory-optimized infrastructure for semantic search and generative AI workloads— vector quantization can further reduce costs and improve performance, even at the highest volume and scale to unlock more use cases.
"Cohere is excited to be one of the first partners to support quantized vector ingestion in MongoDB Atlas,” said Nils Reimers, VP of AI Search at Cohere. “Embedding models, such as Cohere Embed v3, help enterprises see more accurate search results based on their own data sources. We’re looking forward to providing our joint customers with accurate, cost-effective applications for their needs.”
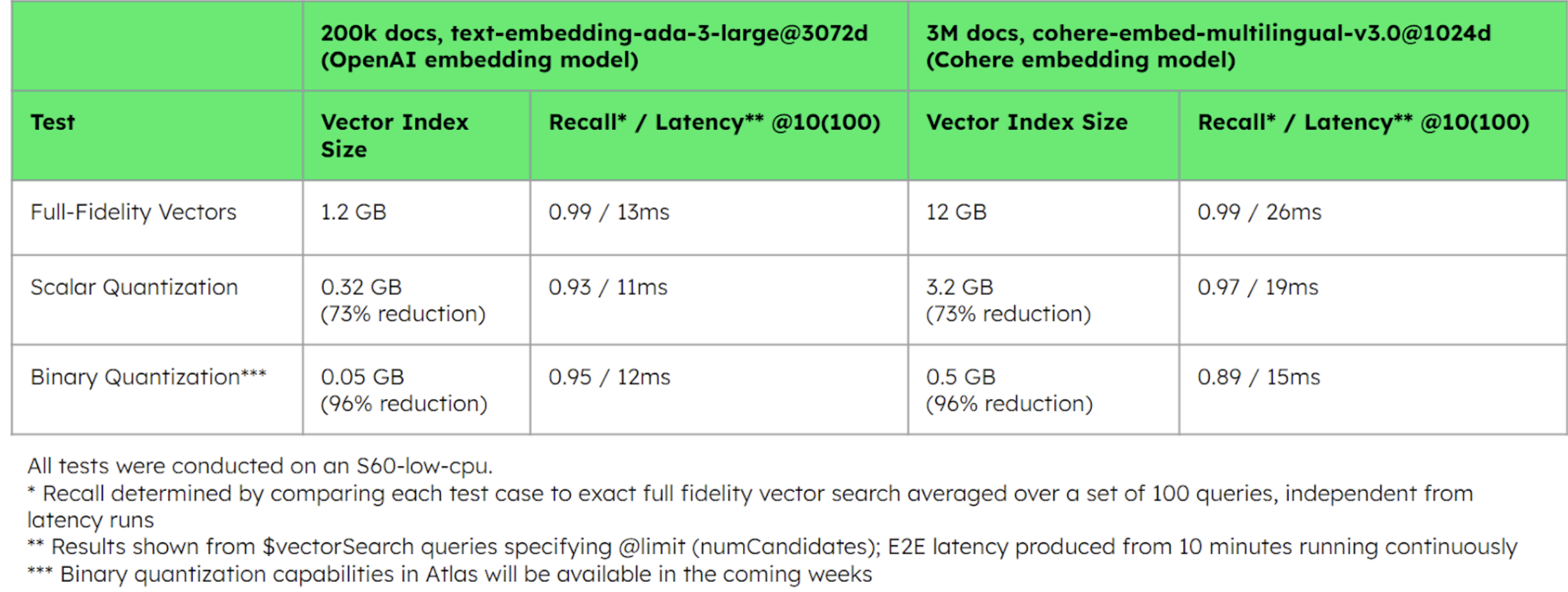
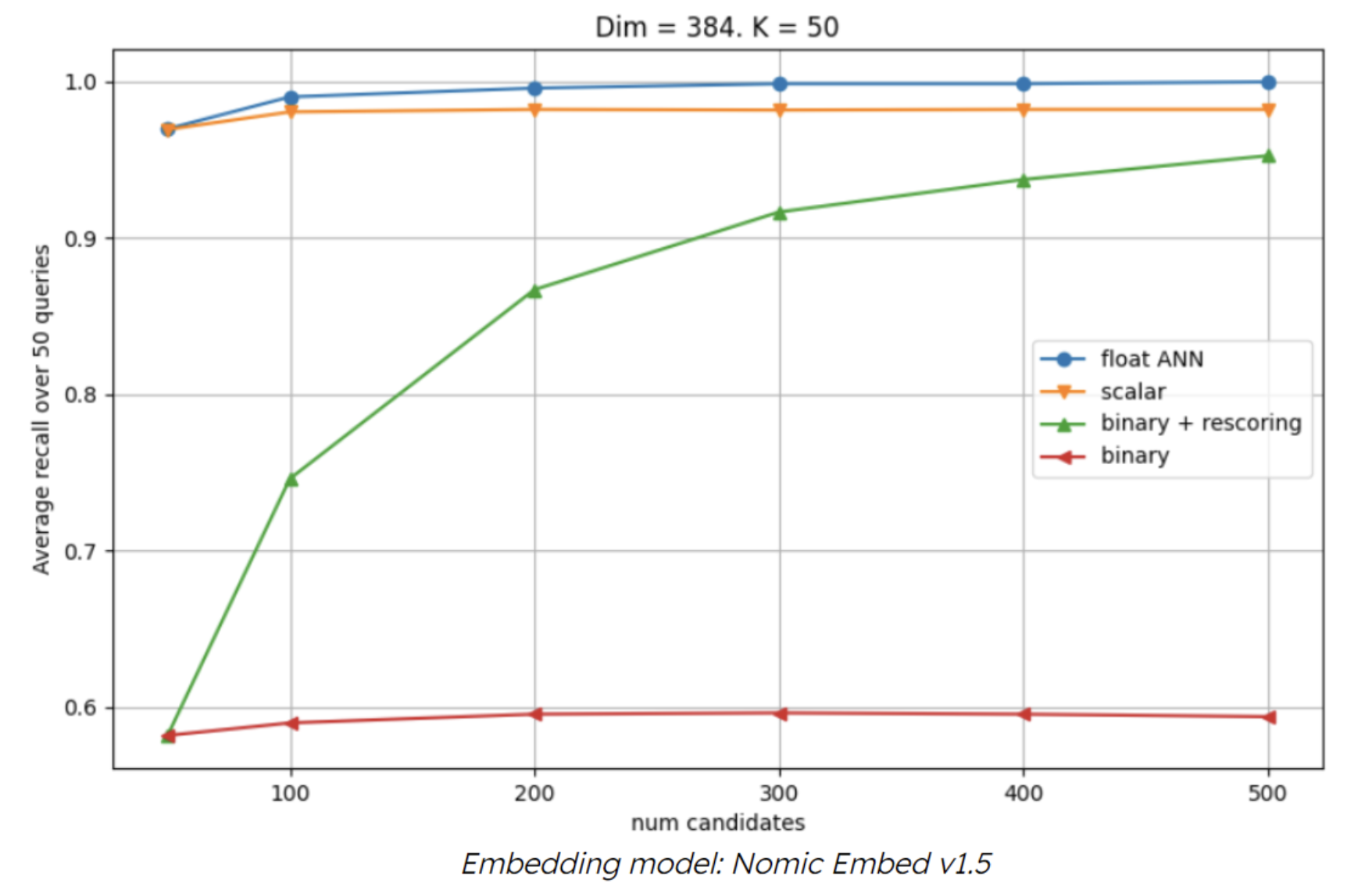
In our tests, compared to full-fidelity vectors, BSON-type vectors—MongoDB’s JSON-like binary serialization format for efficient document storage—reduced storage size by 66% (from 41 GB to 14 GB). And as shown in Figures 2 and 3, the tests illustrate significant memory reduction (73% to 96% less) and latency improvements using quantized vectors, where scalar quantization preserves recall performance and binary quantization’s recall performance is maintained with rescoring–a process of evaluating a small subset of the quantized outputs against full-fidelity vectors to improve the accuracy of the search results.
In addition, thanks to the reduced cost advantage, vector quantization facilitates more advanced, multiple vector use cases that would have been too computationally-taxing or cost-prohibitive to implement. For example, vector quantization can help users:
-
Easily A/B test different embedding models using multiple vectors produced from the same source field during prototyping. MongoDB’s document model—coupled with quantized vectors—allows for greater agility at lower costs. The flexible document schema lets developers quickly deploy and compare embedding models’ results without the need to rebuild the index or provision an entirely new data model or set of infrastructure.
-
Further improve the relevance of search results or context for large language models (LLMs) by incorporating vectors from multiple sources of relevance, such as different source fields (product descriptions, product images, etc.) embedded within the same or different models.
How to get started, and what’s next
Now, with support for the ingestion of scalar quantized vectors, developers can import and work with quantized vectors from their embedding model providers of choice (such as Cohere, Nomic, Jina, Mixedbread, and others)—directly in Atlas Vector Search. Read the documentation and tutorial to get started.
And in the coming weeks, additional vector quantization features will equip developers with a comprehensive toolset for building and optimizing applications with quantized vectors:
Support for ingestion of binary quantized vectors will enable further reduction of storage space, allowing for greater cost savings and giving developers the flexibility to choose the type of quantized vectors that best fits their requirements.
Automatic quantization and rescoring will provide native capabilities for scalar quantization as well as binary quantization with rescoring in Atlas Vector Search, making it easier for developers to take full advantage of vector quantization within the platform.
With support for quantized vectors in MongoDB Atlas Vector Search, you can build scalable and high-performing semantic search and generative AI applications with flexibility and cost-effectiveness. Check out these resources to get started documentation and tutorial.
Head over to our quick-start guide to get started with Atlas Vector Search today.