Data is only valuable if it’s accessible. For example, storing photos, audio files, or PDFs without the ability to extract information from them is like keeping junk in your basement, thinking you might need it someday. The problem is finding what you need to dig through your junk when the day comes.
Until now, companies have followed a similar approach to unstructured data: store everything in data lakes for future use. But whether it’s junk in a basement or data in a data lake, the result is the same: accessibility is hard or impossible.
However, the latest advancements in AI have disrupted this status quo. AI can effectively and efficiently compare similar objects by generating a vector representation or embedding a data object. This capability has revolutionized industries by enabling faster and more precise search, categorization, and recommendation systems than ever before. Whether it's being used to compare text, documents, images, or complex patterns in data, embeddings allow for nuanced interpretations and connections that were impossible with traditional methods. By taking advantage of AI, users can uncover insights and make unprecedented speed and accuracy decisions.
A particularly interesting use case is PDF search, since every company in the world deals with PDFs in one way or another. While PDFs allow portability across platforms and operating systems, most PDF readers only allow for basic exact-match queries.
PDF search powered by MongoDB and Nomic
Enter MongoDB and Nomic: MongoDB Atlas Vector Search with Nomic Embed equips organizations with a powerful and affordable AI-powered search solution for large PDF collections.
A machine learning company specializing in explainable and accessible AI, Nomic Embed is the company’s flagship text embedding model with out-of-the-box features suitable for scalable PDF search. Its features include:
-
Long context: Nomic Embed breaks new ground by supporting a long context length of 8192 tokens, exceeding the standard 2048. This extended context makes the model ideal for real-world applications that involve processing large PDFs and documents.
-
High throughput: While achieving top performance on the MTEB embedding benchmark, Nomic Embed is smaller than similarly performing models. At only 137 million parameters and 548MB, Nomic Embed enables high-throughput embedding generation for data-heavy workflows or streaming applications.
-
Flexible storage: Nomic Embed provides adjustable embedding size via Matryoshka representation learning. Users can freely choose to store the first 64, 128, 256, or 512 embedding dimensions out of the full 768, depending on their project requirements. Smaller embedding sizes come at a minimal performance loss while providing lower storage costs and faster computing benefits.
To put Nomic Embed’s abilities in context, consider a company that processes a high volume of PDFs—say 100,000 documents per month—with an average length of 20 pages each. To improve database retrieval speed, these documents can be partitioned into smaller chunks, such as 2 pages per chunk (see Figure 1 below). Assuming a full page typically contains around 500 words, each document chunk would consist of approximately 1000 words.
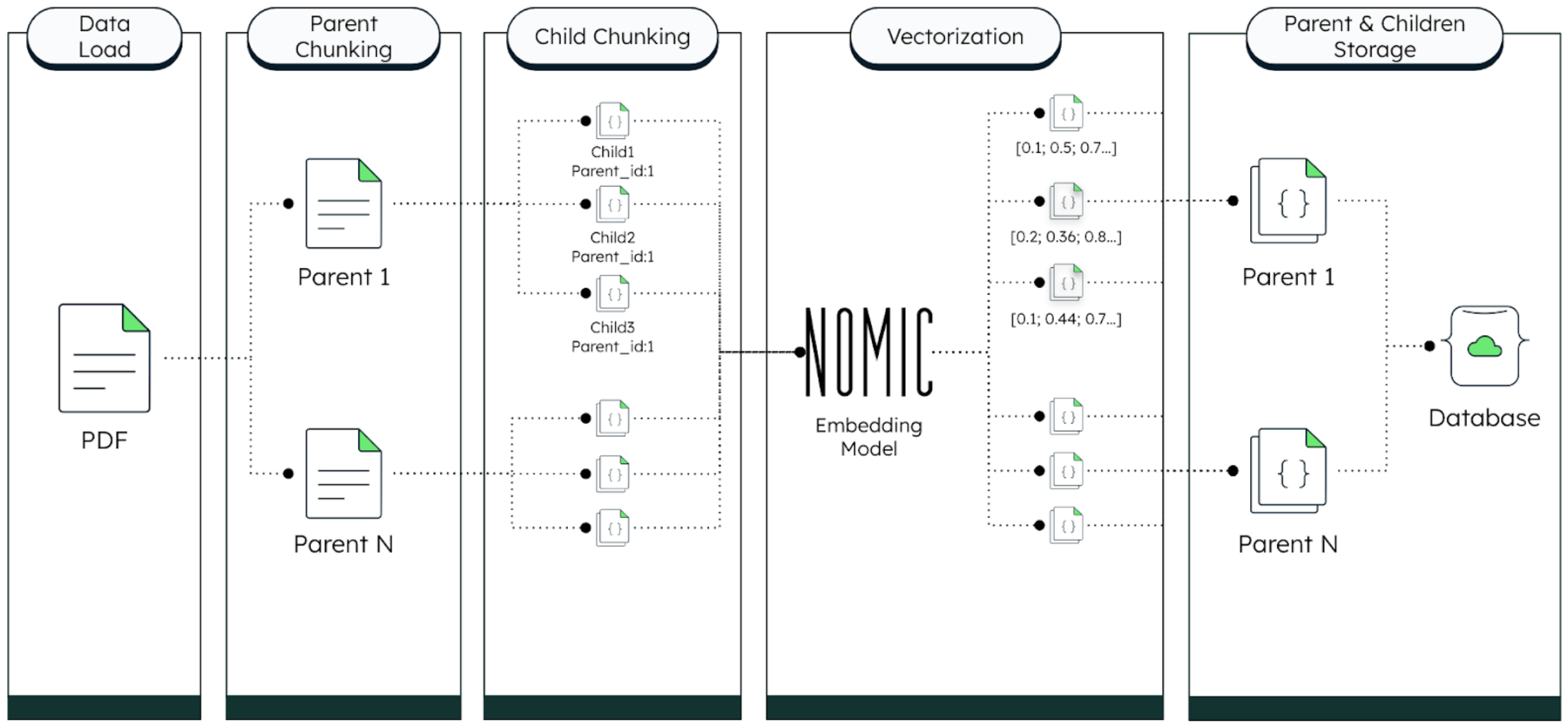
Embedding models process words as numerical tokens where a general rule of thumb is 3/4 word = 1 token. One embedding is more than sufficient to represent a document chunk in this case, as 4/3 * 1000 tokens fit nicely in Nomic Embed’s long context window.
A PDF search application for this company would require 100,000 PDFs x 10 chunks = 1,000,000 embeddings. Benchmarked on Nomic’s AWS Sagemaker real-time inference offering on a single GPU ml.g5.xlarge instance, the total runtime is under 4 hours for a total of $15.60 per month. A similar performing embedding model such as OpenAI’s text-embedding-3-small costs $26.66 per month to generate the same number of embeddings.
Once the embeddings are stored in MongoDB Atlas, it’s possible to create an Atlas Vector Search index to unlock their potential. Building a PDF search application at this point becomes straightforward. The query text is vectorized, and the embedding is fed to Atlas Vector Search to retrieve similar vectors. The result is a list of the most semantically similar sections of the PDF relevant to the original text. This is a significant leap forward compared to a simple “ctrl-f” search, as it captures meaning rather than just keyword matches.
This process can be further improved by implementing a retrieval-augmented generation (RAG) pipeline, combining Atlas Vector Search and a large language model (LLMs). As shown in Figure 2, this approach allows users to ask questions in natural language about the content of the PDF. The relevant documents are then fed to the LLM as context, and the AI is able to provide structured answers by leveraging knowledge about the data.
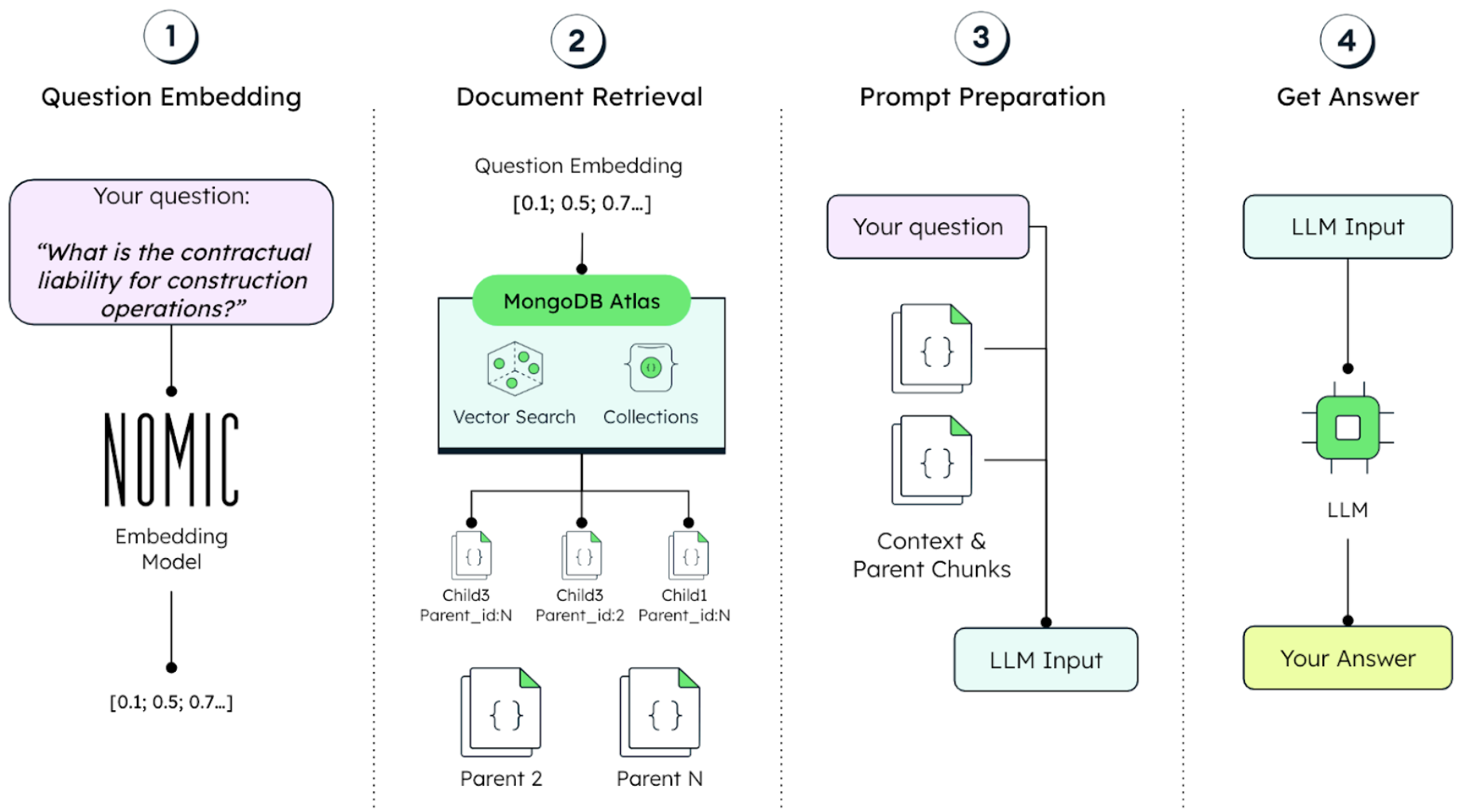
In a nutshell, Nomic and MongoDB provide the building blocks for advanced RAG applications, equipping developers with a cost-effective and integrated toolset.
Seamless integration, supercharged search: Nomic Embeddings in MongoDB Atlas
MongoDB Atlas seamlessly ingests Nomic embeddings with its flexible document storage format. Depending on the application, embeddings and additional metadata can be neatly stored together or separately in MongoDB collections. MongoDB Atlas and Nomic Embed are both available as AWS Marketplace offerings for same-VPC deployments.
MongoDB Atlas Stream Processing is a perfect fit for Nomic Embed’s high throughput capabilities. Incoming data streams are robustly processed and can be combined with MongoDB Database Triggers to generate embeddings for immediate downstream use. Given Nomic Embed’s lightweight nature and offline capabilities (via private or local deployments from open source), embeddings can be produced and ingested into MongoDB at extremely rapid transfer rates.
MongoDB Atlas Vector Search delivers a fast and accessible method to leverage Nomic embeddings for semantic search. MongoDB Atlas Vector Search lets you combine these fast vector search queries with traditional database queries on various metadata, providing a flexible and powerful analytics tool for data insights, user recommendations, and more.
Industry use cases
PDFs are ubiquitous. In one way or another, every company in the world needs to extract and analyze PDF content to make business decisions or comply with regulations. Let’s have a look at some industry use cases:
Financial services
The financial services industry is constantly bombarded with essential updates, including market data, financial statements, and regulatory changes. Some of this information such as financial statements, annual reports, and regulatory filings, resides in PDF format. Efficient and reliable navigation through these documents is crucial for gaining a competitive edge in investment decision-making. For example, investors scrutinize key financial metrics such as revenue growth, profit margins, and cash flow trends extracted from income statements, balance sheets, and cash flow statements. They use this information to compare them between companies, gauging their strategic direction, risks, and competitive positioning before investing. However, accessing and extracting data from these PDFs can be a time-consuming challenge, hindering agility in the fast-paced financial landscape. Here, semantic search for financial PDFs offers a dramatic improvement in information discovery. By leveraging semantic search technology, which interprets the intent and contextual meaning behind a search query, FSI professionals can significantly enhance their ability to find relevant information. This applies equally to the broader financial industry, including areas like market analysis, performance evaluation, and many more.
Retail
In the retail industry, the challenge of processing hundreds of thousands of invoices from numerous suppliers annually is a common scenario. Most invoices are in PDF format, and the challenge arises from the combination of invoice volume and the variability in layouts and languages from one supplier to another. This makes manual processing impractical and error-prone. The question becomes: how can retailers automate this end-to-end process efficiently and accurately? The answer lies in solutions that utilize advanced technologies like AI and PDF search capabilities. By leveraging these solutions, retailers can automatically scan invoices, extract relevant data, and validate it against purchase orders and received goods. Moreover, these solutions offer the flexibility to adapt to different invoice layouts without the need for templates, ensuring scalability and efficiency gains. With increased automation rates and improved accuracy levels, retailers can shift focus from low-value manual tasks to more strategic initiatives, accelerating their digital transformation journey and unlocking significant cost savings along the way.
Manufacturing & motion
There are vast amounts of unstructured data contained in PDFs across the Manufacturing and Automotive industries, from machine instruction booklets to production or maintenance guidelines, Six Sigma best practices, production results, and team lead annotations. All this valuable data must be shared, read, and stored manually, introducing significant friction when it comes to leveraging its full potential. With MongoDB Atlas Vector Search, manufacturing companies have the opportunity to completely revive this data and make real use of it in their day-to-day operations, all while reducing the time spent managing these manuals and having everything ready to be accessed. It is as simple as vectorizing the documents, uploading them to MongoDB Atlas, and connecting a RAG-enabled application to this data source. With this, operators in a manufacturing plant can describe a problem to a smart interface and ask how to troubleshoot it. The interface will retrieve the specific parts of the manual that show how to address the issue. Moreover, it can also retrieve notes from previous operators, team leaders, or previous troubleshooting efforts, providing a very rich context and accelerating the problem-solving process. PDF RAG-enabled applications in manufacturing open up a wide range of operational improvements that directly benefit the company's bottom line.
PDF search at scale
In today’s data-driven world, extracting insights from unstructured data like PDFs is challenging. Traditional search methods fall short, but advancements in AI like Nomic Embed have revolutionized PDF search. By leveraging MongoDB with Nomic Embed, organizations gain a powerful and cost-effective AI-powered solution for large PDF collections. Nomic Embed’s extensive context, high throughput capabilities, and MongoDB’s seamless integration and powerful analytics enable efficient and reliable PDF search applications. This translates to enhanced data accessibility, faster decision-making, and improved operational efficiency.
Don't waste time struggling with traditional PDF search! Apply for an innovation workshop to discuss what’s possible with our industry experts.
If you would like to discover more about MongoDB and GenAI: