Following up on our previous blog, AI, Vectors, and the Future of Claims Processing: Why Insurance Needs to Understand The Power of Vector Databases, we’ll pick up the conversation right where we left it. We discussed extensively how Atlas Vector Search can benefit the claim process in insurance and briefly covered Retrieval Augmented Generation (RAG) and Large Language Models (LLMs).

MongoDB.local NYC
Join us in person on May 2, 2024 for our keynote address, announcements, and technical sessions to help you build and deploy mission-critical applications at scale.
Use Code Web50 for 50% off your ticket!
One of the biggest challenges for claim adjusters is pulling and aggregating information from disparate systems and diverse data formats. PDFs of policy guidelines might be stored in a content-sharing platform, customer information locked in a legacy CRM, and claim-related pictures and voice reports in yet another tool. All of this data is not just fragmented across siloed sources and hard to find but also in formats that have been historically nearly impossible to index with traditional methods. Over the years, insurance companies have accumulated terabytes of unstructured data in their data stores but have failed to capitalize on the possibility of accessing and leveraging it to uncover business insights, deliver better customer experiences, and streamline operations. Some of our customers even admit they’re not fully aware of all the data in their archives. There’s a tremendous opportunity to leverage this unstructured data to benefit the insurer and its customers.
Our image search post covered part of the solution to these challenges, opening the door to working more easily with unstructured data. RAG takes it a step further, integrating Atlas Vector Search and LLMs, thus allowing insurers to go beyond the limitations of baseline foundational models, making them context-aware by feeding them proprietary data. Figure 1 shows how the interaction works in practice: through a chat prompt, we can ask questions to the system, and the LLM returns answers to the user and shows what references it used to retrieve the information contained in the response. Great! We’ve got a nice UI, but how can we build an RAG application? Let’s open the hood and see what’s in it!

Architecture and flow
Before we start building our application, we need to ensure that our data is easily accessible and in one secure place. Operational Data Layers (ODLs) are the recommended pattern for wrangling data to create single views. This post walks the reader through the process of modernizing insurance data models with Relational Migrator, helping insurers migrate off legacy systems to create ODLs.
Once the data is organized in our MongoDB collections and ready to be consumed, we can start architecting our solution. Building upon the schema developed in the image search post, we augment our documents by adding a few fields that will allow adjusters to ask more complex questions about the data and solve harder business challenges, such as resolving a claim in a fraction of the time with increased accuracy. Figure 2 shows the resulting document with two highlighted fields, “claimDescription” and its vector representation, “claimDescriptionEmbedding”. We can now create a Vector Search index on this array, a key step to facilitate retrieving the information fed to the LLM.

Having prepared our data, building the RAG interaction is straightforward; refer to this GitHub repository for the implementation details. Here, we’ll just discuss the high-level architecture and the data flow, as shown in Figure 3 below:
-
The user enters the prompt, a question in natural language.
-
The prompt is vectorized and sent to Atlas Vector Search; similar documents are retrieved.
-
The prompt and the retrieved documents are passed to the LLM as context.
-
The LLM produces an answer to the user (in natural language), considering the context and the prompt.
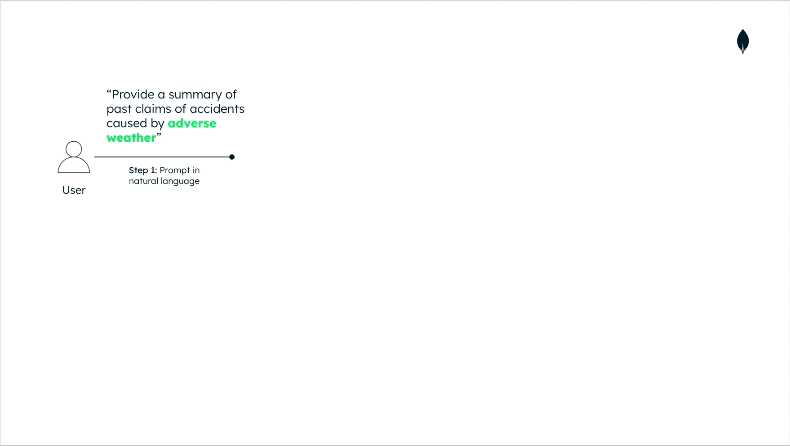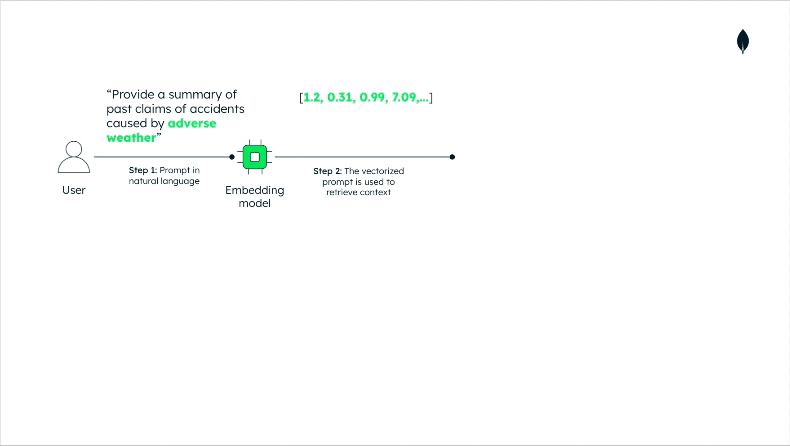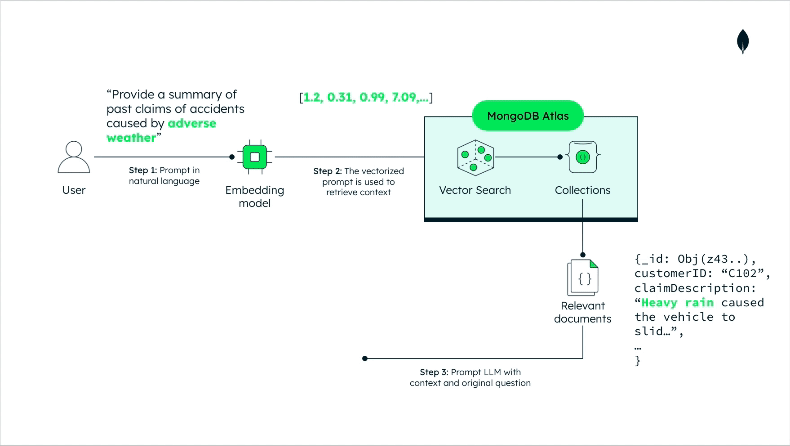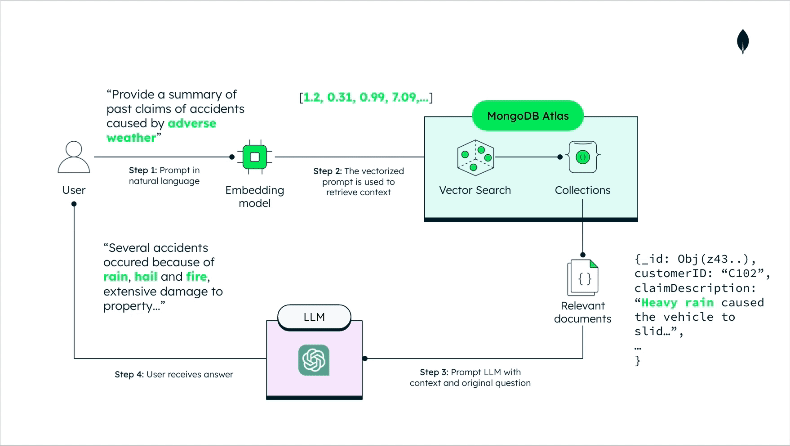
It is important to note how the semantics of the question are preserved throughout the different steps. The reference to “adverse weather” related accidents in the prompt is captured and passed to Atlas Vector Search, which surfaces claim documents whose claim description relates to similar concepts (e.g., rain) without needing to mention them explicitly. Finally, the LLM consumes the relevant documents to produce a context-aware question referencing rain, hail, and fire, as we’d expect based on the user's initial question.
So what?
To sum it all up, what’s the benefit of combining Atlas Vector Search and LLMs in a Claim Processing RAG application?
-
Speed and accuracy: Having the data centrally organized and ready to be consumed by LLMs, adjusters can find all the necessary information in a fraction of the time.
-
Flexibility: LLMs can answer a wide spectrum of questions, meaning applications require less upfront system design. There is no need to build custom APIs for each piece of information you’re trying to retrieve; just ask the LLM to do it for you.
-
Natural interaction: Applications can be interrogated in plain English without programming skills or system training.
-
Data accessibility: Insurers can finally leverage and explore unstructured data that was previously hard to access.
Not just claim processing
The same data model and architecture can serve additional personas and use cases within the organization:
-
Customer Service: Operators can quickly pull customer data and answer complex questions without navigating different systems. For example, “Summarize this customer's past interactions,” “What coverages does this customer have?” or “What coverages can I recommend to this customer?”
-
Customer self-service: Simplify your members’ experience by enabling them to ask questions themselves. For example, “My apartment is flooded. Am I covered?” or “How long do windshield repairs take on average?”
-
Underwriting: Underwriters can quickly aggregate and summarize information, providing quotes in a fraction of the time. For example, “Summarize this customer claim history.” “I Am renewing a customer policy. What are the customer's current coverages? Pull everything related to the policy entity/customer. I need to get baseline info. Find relevant underwriting guidelines.”
If you would like to discover more about Converged AI and Application Data Stores with MongoDB, take a look at the following resources: