我效力于全球领先的文档数据库公司 MongoDB。
文档数据库和关系数据库有很多相似之处,如强类型数据、ACID 事务、富查询、更新和聚合功能,以及索引和 B 树等。文档模型数据库与关系数据库之间的真正不同之处体现在于,它能够在存储和数据建模层一些表格是“碎片”内容嵌入其他表中。这就有点像 RDBMS 中按照索引组织的表格,但对于特定的工作负载,它提供了更大的优化范围。此外,它还能够非常轻松从 Java、C# 和其他现代语言保存对象。
我认为 MongoDB 非常适合电子商务或物流等高吞吐量联机事务处理 (OLTP) 工作负载,既可在其中读写数据,也可将其看作信息源。我还认为(下面将详细说明),对于给定读取/写入/更新工作负载,不论是在单位成本执行的事务数量,还是在每开发小时所开发的功能数量,MongoDB 的效率远远超过 RDBMS。
我没把握的是 MongoDB 的效率比 RDBMS 具体高多少(平心而论,我也没有可复验的证据来验证我的观点)。因此,我花了些时间测量相关值。本文简短介绍了我执行的测试及结果,以及可从何处取得代码来亲自测试。在比较时,我尽力避免参照另一个数据库对一个数据库进行专家式过度调优,因为大部分数据库性能测试都是如此操作。我非常熟悉
MongoDB,但是我会尽量克制自己过度“卖弄”。另一方面,我的确尽我所能地兼顾 PostgreSQL 和 MySQL。我比较熟悉 MySQL。我还使用了这三款数据库的托管版本,因为我希望能够使用由运行这些服务的专家所安装和配置的版本。我的目标是能够在公平的环境中执行公正的测试。当然还得请大家根据我在下方记录的全部数据、测试和调优选项,判断我是否做到客观公平。
我评定了哪些工作负载
我选择模拟英国政府的汽车检测系统。公众可以查询汽车最近的检验以及汽车修理厂,在车辆年检通过或未通过时输入数据。我选择这个的原因是英国政府发布了实际数据、数据的关系架构和查询,以及数据格式指南。
代码测试的内容包括:检索汽车的最新测试详情、添加新汽车、未能通过汽车测试,以及修改现有结果以更正行驶里程。不同测试所用的比率也不同。我加载了 2021 年的全部数据,刚刚超过 4000 万个测试结果。
数据库和客户端托管选择
我的测试全部都在主要云提供商环境中完成。我使用的是与数据库位于同一个区域的托管 Unix 服务器,为各案例执行测试应用程序。我使用 MongoDB Atlas 来执行 MongoDB 副本集,也使用了该云提供商的托管 MySQL 和 PostgreSQL 产品组合。我尽量保留相同的实例规格,为保证透明度,我选择同时显示规格和每小时定价。
代码
我用的代码是多线程 Java。我将 MongoDB Java 驱动程序用于 Atlas,将 JDBC 用于 MySQL 和 Postgres。值得注意的是,MongoDB 只需要 20% 的代码行就能够读取和写入数据库,因为不需要在一个事务中执行多次插入就能够保留和检索对象,也不需要从多行重建对象。
可检索对象并将其从 MongoDB 转换为 JSON 的代码如下。
public String getMOTResultInJSON(String identifier) {
 long identifierLong;
 try {
 identifierLong = Long.valueOf(identifier);
 Bson byIdQuery = Filters.eq("vehicleid", identifierLong);
 testObj = testresults.find(byIdQuery).limit(1).first();
 if (testObj != null) {
 return testObj.toJson();
 }
 } catch (Exception e) {
 logger.error(e.getLocalizedMessage());
 }
 return "{ }"; // Not found
 }
相对于适用于 RDBMS 的代码,适合只有一个嵌套层的对象。
//Query From https://data.dft.gov.uk/anonymised-mot-test/MOT_user_guide_v4.docx
private final String getlatestByVehicleSQL = "select " +
"tr.*, " +
"ft.FUEL_TYPE, " +
"tt.TESTTYPE AS TYPENAME, " +
"to2.RESULT, " +
"ti.*, " +
"fl.*, " + "tid.MINORITEM,tid.RFRDESC,tid.RFRLOCMARKER,tid.RFRINSPMANDESC,tid.RFRADVISORYTEXT,tid.TSTITMSETSECID, " +
"b.ITEMNAME AS LEVEL1, " +
"c.ITEMNAME AS LEVEL2, " +
"d.ITEMNAME AS LEVEL3, " +
"e.ITEMNAME AS LEVEL4, " +
"f.ITEMNAME AS LEVEL5 " +
"from TESTRESULT tr " +
"LEFT JOIN TESTITEM ti on ti.TESTID = tr.TESTID " +
"LEFT JOIN FUEL_TYPES ft on ft.TYPECODE = tr.FUELTYPE " +
"LEFT JOIN TEST_TYPES tt on tt.TYPECODE = tr.TESTTYPE " +
 "LEFT JOIN TEST_OUTCOME to2 on to2.RESULTCODE = tr.TESTRESULT " +
"LEFT JOIN FAILURE_LOCATION fl on ti.LOCATIONID = fl.FAILURELOCATIONID " +
"LEFT JOIN TESTITEM_DETAIL AS tid ON ti.RFRID = tid.RFRID AND tid.TESTCLASSID = tr.TESTCLASSID " +
"LEFT JOIN TESTITEM_GROUP AS b ON tid.TSTITMID = b.TSTITMID AND tid.TESTCLASSID = b.TESTCLASSID " +
"LEFT JOIN TESTITEM_GROUP AS c ON b.PARENTID = c.TSTITMID AND b.TESTCLASSID = c.TESTCLASSID " +
"LEFT JOIN TESTITEM_GROUP AS d ON c.PARENTID = d.TSTITMID AND c.TESTCLASSID = d.TESTCLASSID " +
"LEFT JOIN TESTITEM_GROUP AS e ON d.PARENTID = e.TSTITMID AND d.TESTCLASSID = e.TESTCLASSID " +
"LEFT JOIN TESTITEM_GROUP AS f ON e.PARENTID = f.TSTITMID AND e.TESTCLASSID = f.TESTCLASSID " +
"WHERE tr.TESTID = (SELECT TESTID FROM TESTRESULT WHERE VEHICLEID=? LIMIT 1)";


public String getMOTResultInJSON(String identifier) {
 long identifierLong;
 jsonObj = new JSONObject();
 // Check we aren't a new thread - if we are we need a new conneciton.
 try {
 identifierLong = Long.valueOf(identifier);
 //Pick a prepared statement from out list of readers randomly
 PreparedStatement getTestStmt = readConnections.get(ThreadLocalRandom.current().nextInt(0, readConnections.size()));
 getTestStmt.setLong(1, identifierLong);
 ResultSet testResult = getTestStmt.executeQuery();
 ResultSetMetaData metaData = testResult.getMetaData();
 
 // Create JSON from a set of Rows
 String[] topFieldNames = { "TESTID", "VEHICLEID", "TESTTYPE", "TESTRESULT", "TESTDATE", "TESTCLASSID", "TYPENAME","TESTMILEAGE", "POSTCODEREGION", "MAKE", "MODEL", "COLOUR", "FUELTYPE", "FUEL_TYPE", "CYLCPCTY","FIRSTUSEDATE","RESULT" };
 
 String[] itemFieldNames = { "RFRID", "RFRTYPE", "DMARK", "LOCATIONID", "LAT", "LONGITUDINAL", "VERTICAL","MINORITEM", "RFRDESC","RFRLOCMARKER", "RFRINSPMANDESC", "RFRADVISORYTEXT", "LEVEL1", "LEVEL2", "LEVEL3", "LEVEL4", "LEVEL5" };


 boolean firstRow = true;
 JSONArray itemsJSON = new JSONArray();
 while (testResult.next()) {
;
 JSONObject itemJSON = new JSONObject();
 for (int col = 1; col <= metaData.getColumnCount(); col++) {
 String label = metaData.getColumnLabel(col);
 
 if (firstRow && Arrays.asList(topFieldNames)
 .contains(label.toUpperCase())) {
 Object val = testResult.getObject(col);
 
 jsonObj.put(label.toLowerCase(), val);
 }
 // All Rows add to the Items array - this is a simple JSON structure
 // Wiith just one top level array of objects
 if (Arrays.asList(itemFieldNames).contains(label.toUpperCase())) {
 Object val = testResult.getObject(col);
 itemJSON.put(label.toLowerCase(), val);
 }
 }
 /* If our item isnt blank add it to the items JSONArray */
 if (itemJSON.optInt("rfrid", -1) != -1) {
 itemsJSON.put(itemJSON);
 }
 firstRow = false;
 }
 jsonObj.put("testitems", itemsJSON);
 testResult.close();
 return jsonObj.toString();
 } catch (Exception e) {
 e.printStackTrace();
 logger.error(e.toString());
 }
 return jsonObj.toString();
}
可以访问我的 GitHub 存储库中的代码。该存储库提供下载及清理数据所需的全部说明。 (它里面有几处错误,例如奇数重复键。它还缺失显式 NULL 值,因此 PostgreSQL 所报告的 CSV 中缺失值是字符串。)将数据加载到 PostgreSQL 或 MySQL 中,再将其转换为对象,最后再从 PostgreSQL 或 MySQL 加载到 MongoDB 中。由于测试用具拥有可从 RDBMS 创建对象的代码,因此,将数据加载到 MongoDB 的最简单方式是从 MySQL 将其读取为对象,再将这些对象写入 Atlas。
结果
执行第一个测试时,针对 Atlas 和云提供商使用了推荐的最小“生产”设置。生产指的是包括适用于灾难恢复 (DR) 和读取扩展之副本的最低等级,依赖的是专用计算,而不是可突发计算,以确保性能可预测。MongoDB Atlas 拥有 3 个数据库实例并搭载 2 个 vCPU 核心和 8GB RAM,而 MySQL 和 Postgres 则拥有 2 个实例并搭载 2 个 vCPU 核心和 16GB RAM。数据是一样的。
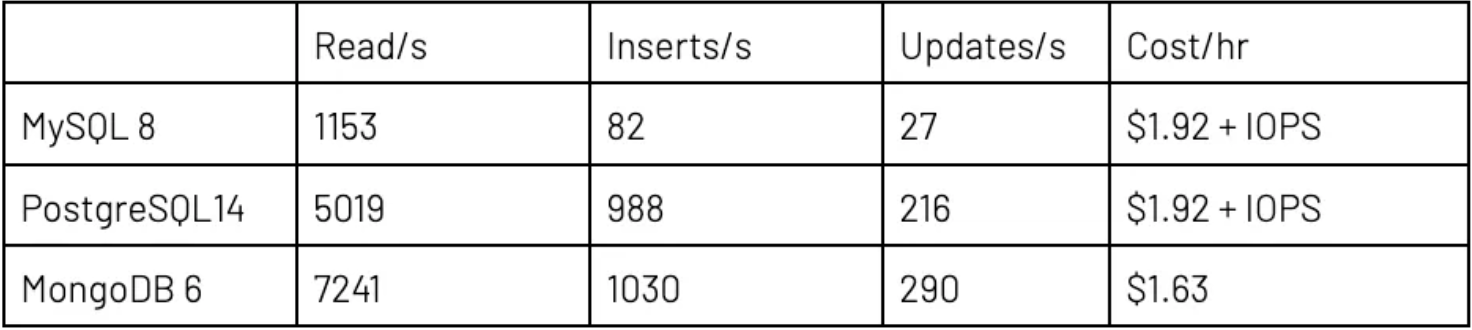
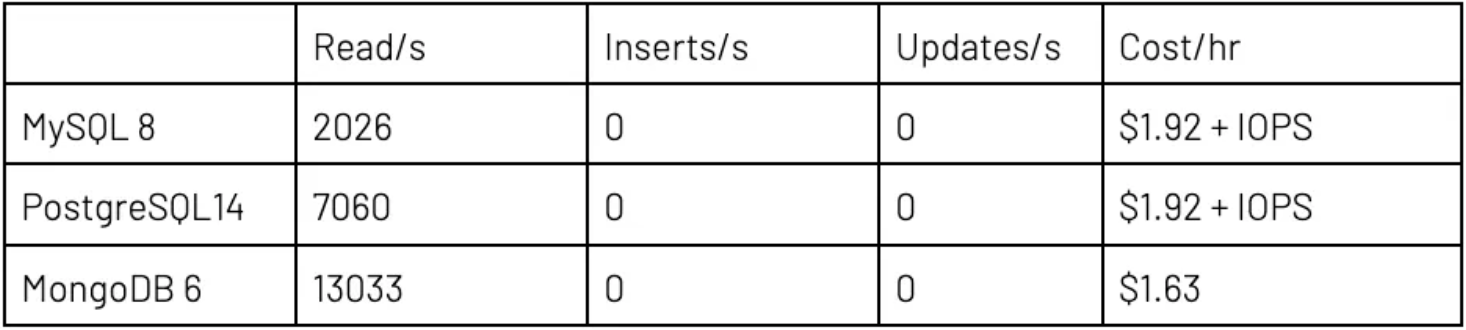
对于读取/插入/更新工作负载,要求执行之线程的比率为 85:15:5;而只读工作负载的比率为 100:0:0。总体来看,在小型服务器上,我使用了 100 个线程;而通过大型数据库服务器完成测试时使用了 300 个。 我测试了两种情况,即,只从primary/写入程序实例(单一服务器)读取但由其他实例提供 DR/HA 容错功能;以及,将读取分发到secondary/读取程序实例(包括读取副本)。在小型数据库设置中,MongoDB 拥有两个次要节点(允许的最小值),而 MySQL 和 Postgres 只拥有一个节点(允许的最小值)。MongoDB Atlas 三节点配置的每小时总价仍然稍低于云提供商的双节点解决方案。
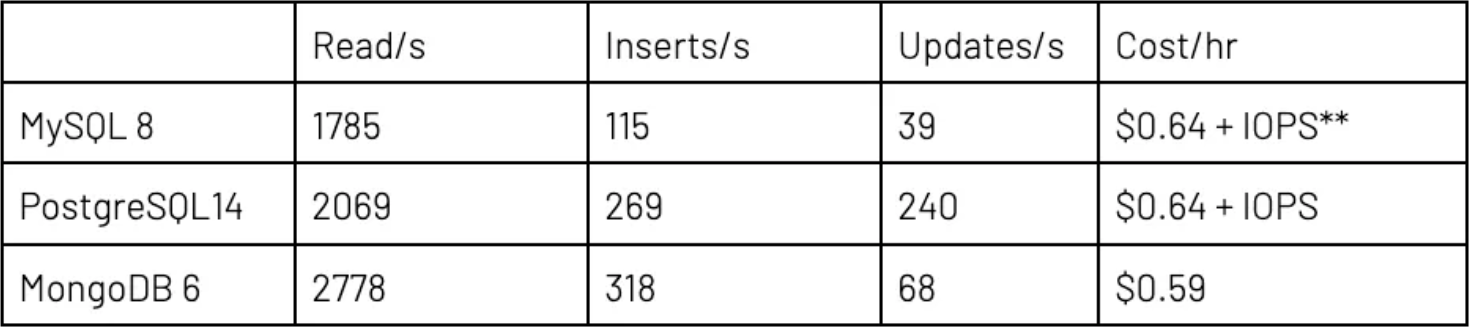
IOPS 定价的重要提示:对于 RDBMS,磁盘读取和写入收费为每 100 万次 I/O 操作 0.22 美元。这几个测试下来,可以得出使用计算实例的成本每小时可增加 50% 到 250% 不等。MongoDB Atlas 定价包括所有磁盘成本。
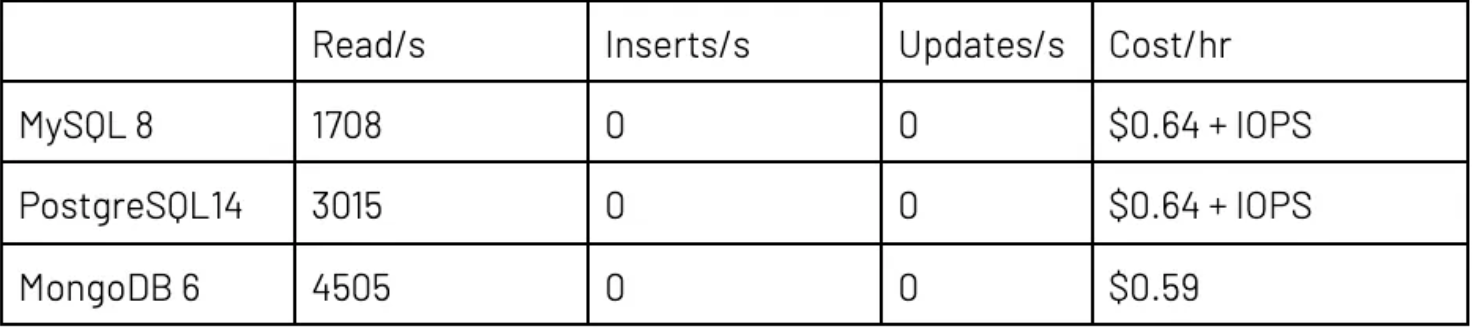
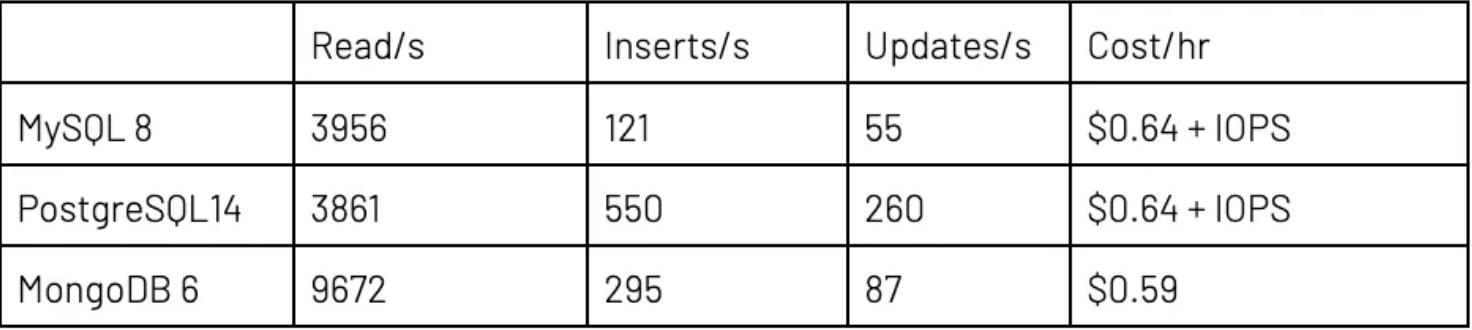
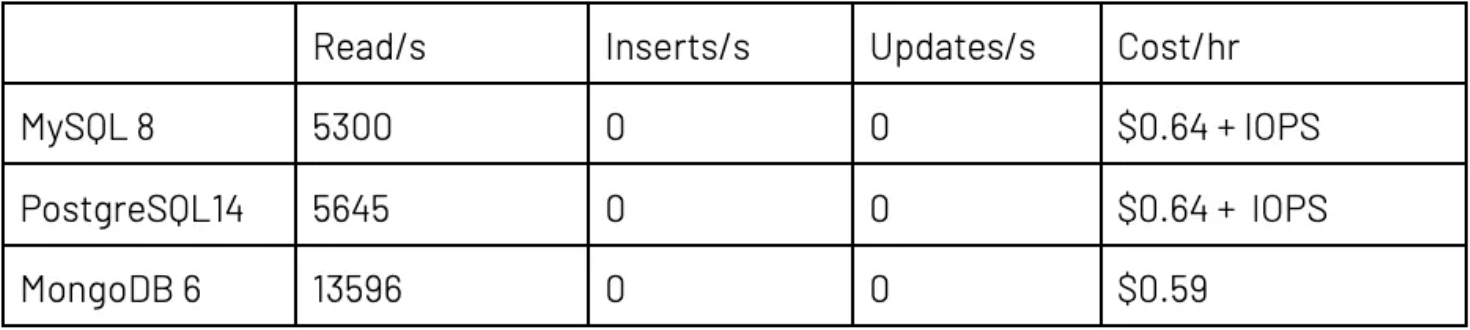
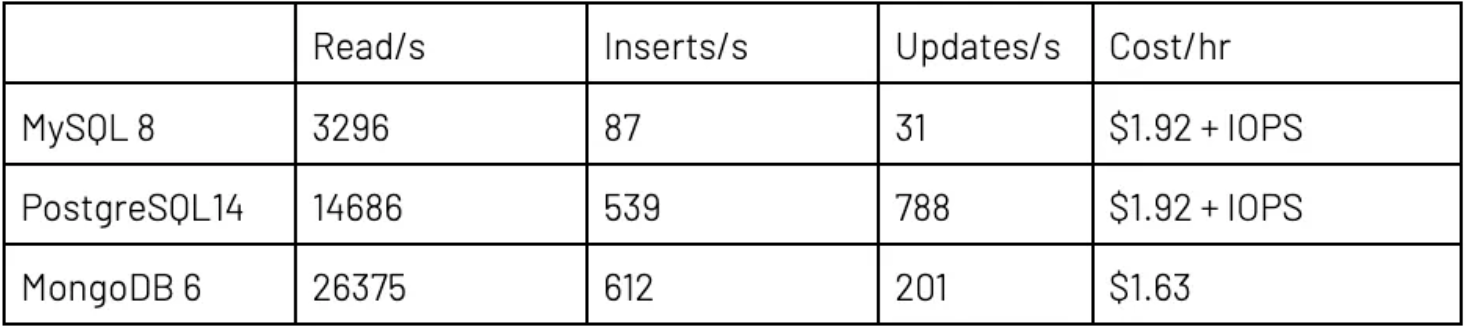
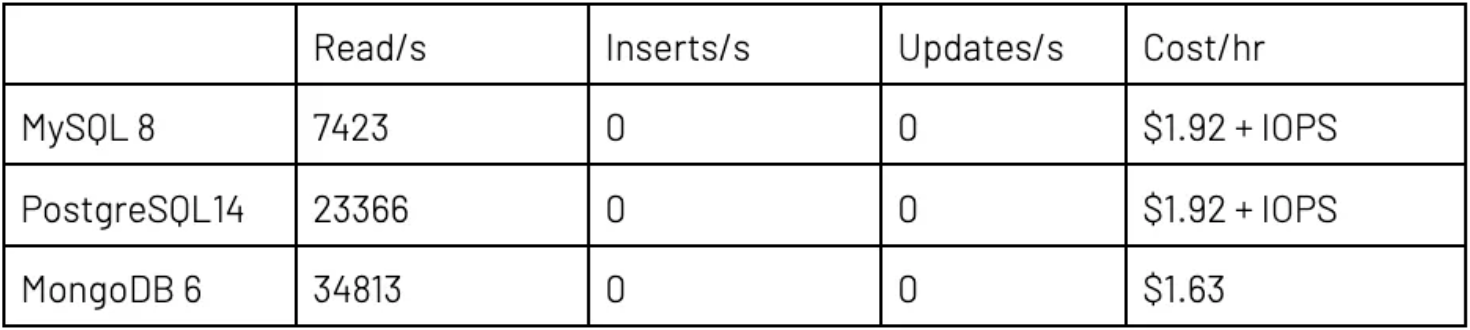
执行第二个测试时,针对 Atlas 和云提供商使用了较大“生产”设置。该设置包括适用于 DR 和读取扩展的 3 个副本,以及足够 RAM 来确保 RDBMS 能够让工作集保留在缓存中。RDBMS 和 MongoDB Atlas 都拥有 3 个数据库实例,以及 4 个 CPU 和 32GB RAM。数据与上次测试一样。比率相同的情况下,线程的总数量从 100 个增加到 300 个。
注意事项与结论
结果的差异大到令人咋舌。看起来,MySQL 处理大量并行线程的能力尤其低下。背后原因很可能是服务器调整问题。添加写入和更新后,与只读相比,MySQL 和 MongoDB 的每线程读取量都相对下降。
在读取方面,MongoDB Atlas 比 PostgreSQL 快 50–100%,比 MySQL 快得多。这个结果证实了我的预判。此外,每笔事务也实惠许多,要知道全部 I/O 成本都已纳入 Atlas 中,而云提供商 RDBMS 则产生了额外、非常大额 IOPS 成本。
MongoDB 会压缩磁盘上的数据,但是在缓存中不会经过压缩。也就是说,与 RDBMS 不同,Atlas 永远无法保留 RAM 格式的 45 GB 数据,且其速度与 I/O 息息相关。我没有使用 $lookup(相当于 MongoDB 的 LEFT JOIN),因此总体并不复杂。文档包含来自小型域表格的 200+ 个字符串说明,主要介绍了失败项。在这种情况下,最好是 $lookup 查询中的这些说明,而不是将其存储在数据中。此时,一股脑嵌入所有内容没用,了解如何充分利用文档模型才能带来丰厚回报。我可以扩展测试来演示这个效果,因为让数据缓存应当能够进一步优化速度。
PostgreSQL 和 MongoDB 在新数据插入速率上的表现相当,MongoDB 快 5–10%,但有一个例外,因此很可能需要重新测试或进一步调查。在 MongoDB 中更新操作比 PostgreSQL 慢二到四倍,但仍比 MySQL 快。这个结果在意料之内,因为我们在大得多的文档中更改单一值,因此在写出更改方面,MongoDB 的 I/O 比 PostgreSQL 多。前面提到使用 $lookup 的建议能够将文档大小从平均 1260 字节减少到平均 895 字节,显著提高读取和写入的速度。
仍有疑问?试试复刻我的代码后再执行几个测试。真实的 OLTP 会输入的内容包括多张表格、复杂的更新和并行,而不是对随机数据的键/值检索,后者的推出往往是为了比较数据库模型。可注册 阿里云版MongoDB https://free.aliyun.com/pipCode=mongodb&utm_content=m_1000371601 进行试用。