¡Hoy nos complace anunciar la vista previa privada de Atlas Stream Processing!
El mundo avanza cada vez más rápido y sus aplicaciones deben mantenerse al día. Las aplicaciones responsivas basadas en eventos dan vida a las experiencias digitales para sus clientes y aceleran el tiempo de obtención de conocimientos y acción para el negocio. Pensar:
-
notificar a sus usuarios tan pronto como cambie el estado de su entrega
-
bloquear transacciones fraudulentas durante el procesamiento de pagos
-
analizar la telemetría del sensor a medida que se genera para detectar y remediar posibles fallas del equipo antes de costosas interrupciones.
En cada uno de estos ejemplos, los datos pierden su valor a medida que pasan los segundos. Es necesario consultarlo y actuar de forma continua y con baja latencia. Para hacer esto, los desarrolladores recurren cada vez más a aplicaciones impulsadas por eventos alimentadas por transmisión de datos para que puedan reaccionar y responder instantáneamente al mundo en constante cambio que los rodea. Atlas Stream Processing ayudará a los desarrolladores a hacer el cambio más rápido hacia aplicaciones basadas en eventos.
A lo largo de los años, los desarrolladores han adoptado la base de datos MongoDB porque les encanta la flexibilidad y facilidad de uso del modelo de documento, junto con la MongoDB Query API que les permite trabajar con datos como código. Estos principios fundamentales eliminan drásticamente la fricción en el desarrollo de software y aplicaciones. Ahora, estamos incorporando esos mismos principios a la transmisión de datos. Atlas Stream Processing está redefiniendo la experiencia de los desarrolladores para trabajar con flujos complejos de alta velocidad, datos que cambian rápidamente y unificando la forma en que los desarrolladores trabajan con datos en movimiento y en reposo.
Si bien los productos y tecnologías existentes han ofrecido muchas innovaciones para la transmisión y el procesamiento de transmisiones, creemos que MongoDB es naturalmente muy adecuado para ayudar a los desarrolladores con algunos desafíos clave pendientes. Estos desafíos incluyen la dificultad de trabajar con datos variables, de gran volumen y alta velocidad; la sobrecarga contextual de aprender nuevas herramientas, lenguajes y API; y el mantenimiento operativo adicional y la fragmentación que se pueden introducir a través de tecnologías puntuales en pilas de aplicaciones complejas.
Presentamos el procesamiento Atlas Stream
Atlas Stream Processing permite procesar flujos de datos complejos a alta velocidad con algunas ventajas únicas para la experiencia del desarrollador:
-
Está construido sobre el modelo de documento, lo que permite flexibilidad al tratar con estructuras de datos complejas y anidadas comunes en flujos de eventos. Esto alivia la necesidad de pasos de preprocesamiento y al mismo tiempo permite a los desarrolladores trabajar de forma natural y sencilla con datos que tienen estructuras complejas. Tal como lo permite la base de datos.
-
Unifica la experiencia de trabajar con todos los datos, ofreciendo una única plataforma (a través de API, lenguaje de consulta y herramientas) para procesar datos de transmisión ricos y complejos junto con los datos de aplicaciones críticas en su base de datos.
-
Y se administra completamente en MongoDB Atlas, basándose en un conjunto ya sólido de servicios integrados. Con solo unas pocas llamadas API y líneas de código, puede implementar un procesador de flujo, una base de datos y una capa de servicio API en cualquiera de los principales proveedores de nube.
¿Cómo funciona el procesamiento Atlas Stream?
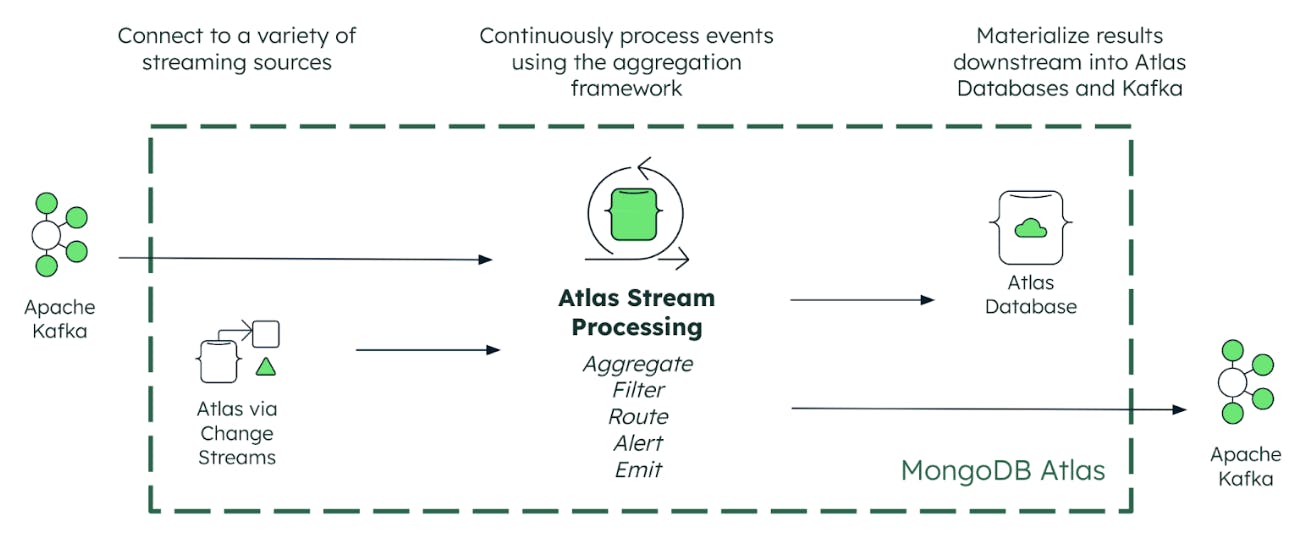
Atlas Stream Processing se conecta a sus datos críticos, ya sea que se encuentren en MongoDB (a través de change streams) o en una plataforma de transmisión de eventos como Apache Kafka. Los desarrolladores pueden conectarse fácil y sin problemas a Confluent Cloud, Amazon MSK, Redpanda, Azure Event Hubs o Kafka autoadministrado mediante el protocolo de conexión Kafka. Y al integrarse con el controlador nativo Kafka, Atlas Stream Processing ofrece un rendimiento nativo de baja latencia como base.
Además de nuestra asociación estratégica de larga data con Confluent, también nos complace anunciar asociaciones con AWS, Microsoft, Redpanda y Google en el lanzamiento.
Luego, Atlas Stream Processing proporciona tres capacidades clave necesarias para convertir su fuente de transmisión de datos en experiencias diferenciadas para el cliente. Repasemos estos uno por uno.
Procesamiento continuo
En primer lugar, los desarrolladores ahora pueden utilizar el marco de agregación de MongoDB para procesar continuamente flujos de datos ricos y complejos desde plataformas de transmisión de eventos como Apache Kafka. Esto desbloquea nuevas y poderosas formas de consultar, analizar y reaccionar continuamente a la transmisión de datos sin ninguno de los retrasos inherentes al procesamiento por lotes. Con el marco de agregación, puede filtrar y agrupar datos, agregando flujos de eventos de alta velocidad en información procesable a través de ventanas de tiempo con estado, impulsando experiencias de aplicaciones más ricas en tiempo real.
Validación continua
A continuación, Atlas Stream Processing ofrece a los desarrolladores mecanismos nativos y sólidos para manejar problemas de datos incorrectos que, de otro modo, podrían causar estragos en las aplicaciones. Los posibles problemas incluyen pasar resultados inexactos a la aplicación, pérdida de datos y tiempo de inactividad de la aplicación. Atlas Stream Processing resuelve estos problemas para garantizar que los datos de transmisión se puedan procesar y compartir de manera confiable entre aplicaciones controladas por eventos.
Procesamiento de corriente Atlas:
-
Proporciona validación continua de esquemas para verificar que los eventos estén formados correctamente antes de procesarlos; por ejemplo, rechazar eventos a los que les faltan campos o que contienen rangos de valores no válidos.
-
Detecta corrupción de mensajes
-
Detecta datos que llegan tarde y que han perdido una ventana de procesamiento.
Las canalizaciones de Atlas Stream Processing se pueden configurar con una cola de mensajes fallidos (DLQ) integrada a la que se enrutan los eventos que no superan la validación. Esto evita que los desarrolladores tengan que crear y mantener sus propias implementaciones personalizadas. Los problemas se pueden depurar rápidamente mientras se minimiza el riesgo de que falten datos o que se dañen toda la aplicación.
Fusión continua
Sus datos procesados pueden luego materializarse continuamente en vistas mantenidas en las colecciones de la base de datos Atlas. Podemos pensar en esto como una consulta push. Las aplicaciones pueden recuperar resultados (mediante consultas de extracción) de la vista utilizando MongoDB Query API o la interfaz Atlas SQL. La fusión continua de actualizaciones de las colecciones es una forma realmente eficiente de mantener nuevas vistas analíticas de los datos que respaldan la toma de decisiones y la acción humana y automatizada. Además de las vistas materializadas, los desarrolladores también tienen la flexibilidad de publicar eventos procesados en sistemas de transmisión como Apache Kafka.
Creando un procesador de flujo
Le mostraremos lo fácil que es construir un procesador de flujo en MongoDB Atlas. Con Atlas Stream Processing, puede utilizar la misma sintaxis de canalización de agregación para un procesador de flujo con el que está familiarizado en la base de datos. A continuación mostramos una instancia de procesamiento de flujo simple de principio a fin. Sólo se necesitan unas pocas líneas de código.
Primero, escribiremos un canal de agregación que defina una fuente para sus datos, realice una validación para garantizar que los datos no provengan de la dirección IP localhost/127.0.0.1, cree una ventana giratoria para recopilar datos de mensajes agrupados cada minuto y luego los fusionaremos. datos recién procesados en una colección de MongoDB en Atlas.
Luego, crearemos nuestro Stream Processor llamado “netattacks” especificando nuestra canalización p recién definida así como dlq como argumentos. Esto realizará el procesamiento deseado y, mediante el uso de una cola de mensajes fallidos (DLQ), almacenará de forma segura los datos no válidos para su inspección, depuración o reprocesamiento posterior.
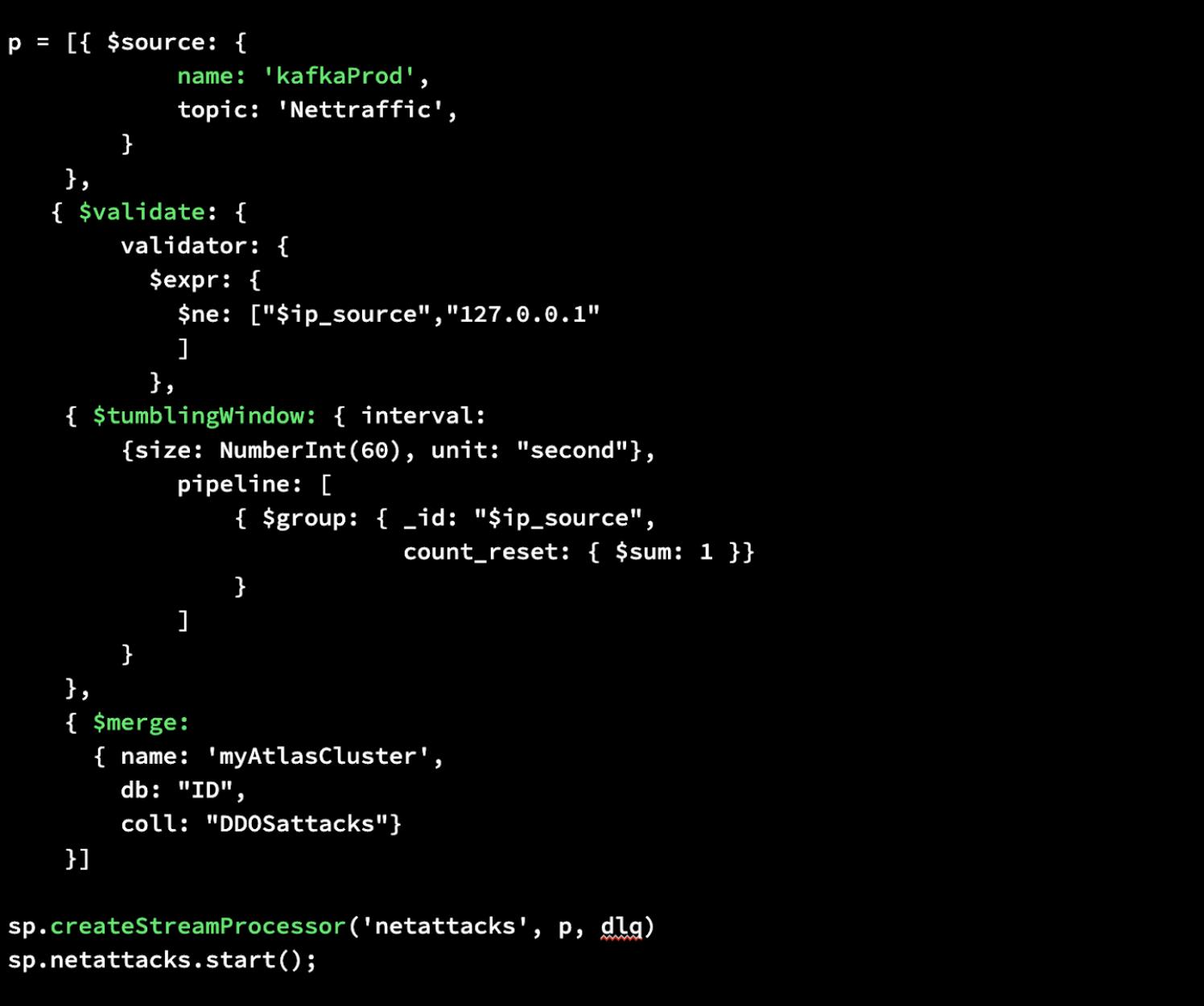
Por último, podemos iniciarlo. Eso es todo lo que se necesita para construir un procesador de flujo en MongoDB Atlas.
Solicitar vista previa privada
Estamos emocionados de tener este producto en sus manos y ver qué construye con él. Obtenga más información sobre Atlas Stream Processing y solicite acceso temprano aquí para participar en la vista previa privada una vez que esté abierta a los desarrolladores.
¿Nuevo en MongoDB? Comience gratis hoy registrándose en MongoDB Atlas.
Puerto seguro
El desarrollo, lanzamiento y calendario de cualquier característica o funcionalidad descrita para nuestros productos queda a nuestro exclusivo criterio. Esta información tiene como único objetivo describir la dirección general de nuestro producto y no se debe confiar en ella para tomar una decisión de compra ni es un compromiso, promesa u obligación legal de entregar ningún material, código o funcionalidad.