Today, we’re excited to announce the private preview of Atlas Stream Processing!
The world is increasingly fast-paced and your applications need to keep up. Responsive, event-driven applications bring digital experiences to life for your customers and accelerate time to insight and action for the business. Think:
-
Notifying your users as soon as their delivery status changes
-
Blocking fraudulent transactions during payment processing
-
Analyzing sensor telemetry as it is generated to detect and remediate potential equipment failures before costly outages.
In each of these examples, data loses its value as the seconds tick by. It needs to be queried and actioned continuously and with low latency. To do this, developers are increasingly turning to event-driven applications fueled by streaming data so that they can instantly react and respond to the constantly changing world around them. Atlas Stream Processing will help developers make the shift to event-driven apps faster.
Over the years, developers have adopted the MongoDB database because they love the flexibility and ease of use of the document model, along with the MongoDB Query API which allows them to work with data as code. These foundational principles dramatically remove friction from developing software and applications. Now, we are bringing those same principles to streaming data. Atlas Stream Processing is redefining the developer experience for working with complex streams of high velocity, rapidly changing data, and unifying how developers work with data in motion and at rest.
While existing products and technologies have offered many innovations to streaming and stream processing, we think MongoDB is naturally well suited to help developers with some key remaining challenges. These challenges include the difficulty of working with variable, high volume, and high-velocity data; the contextual overhead of learning new tools, languages, and APIs; and the additional operational maintenance and fragmentation that can be introduced through point technologies into complex application stacks.
Introducing Atlas Stream Processing
Atlas Stream Processing enables processing high-velocity streams of complex data with a few unique advantages for the developer experience:
-
It’s built on the document model, allowing for flexibility when dealing with the nested and complex data structures common in event streams. This alleviates the need for pre-processing steps while allowing developers to work naturally and easily with data that has complex structures. Just as the database allows.
-
It unifies the experience of working across all data, offering a single platform – across API, query language, and tools – to process rich, complex streaming data alongside the critical application data in your database.
-
And it’s fully managed in MongoDB Atlas, building on an already robust set of integrated services. With just a few API calls and lines of code, you can stand up a stream processor, database, and API serving layer across any of the major cloud providers.
How does Atlas Stream Processing work?
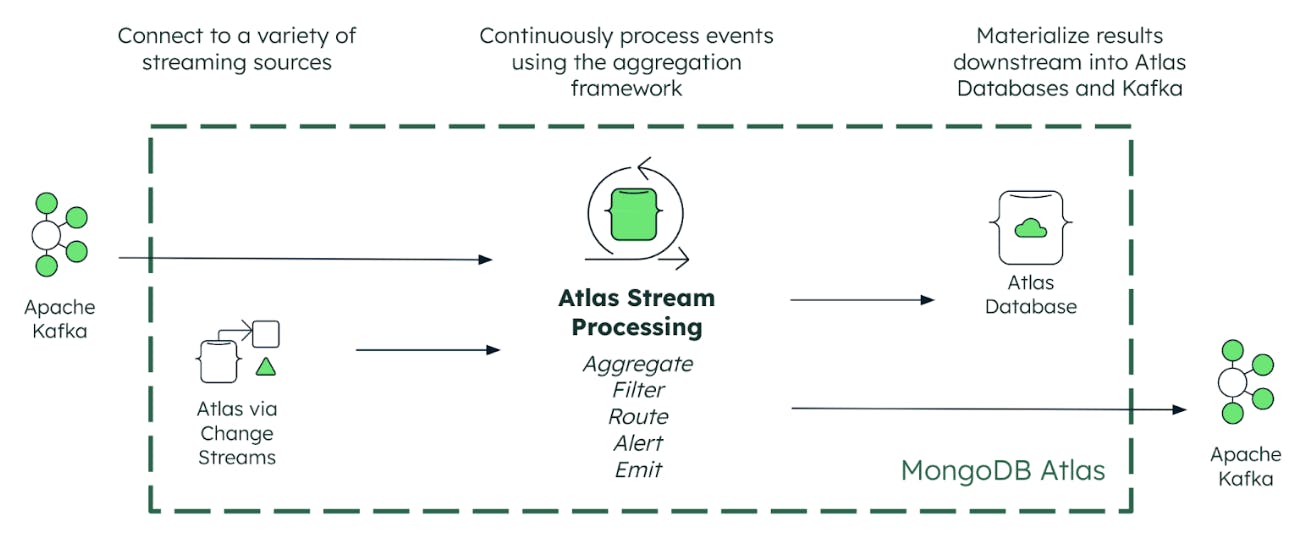
Atlas Stream Processing connects to your critical data, whether that lives in MongoDB (through change streams) or in an event streaming platform like Apache Kafka. Developers can easily and seamlessly connect to Confluent Cloud, Amazon MSK, Redpanda, Azure Event Hubs, or self-managed Kafka using the Kafka wire protocol. And by integrating with the native Kafka driver, Atlas Stream Processing offers low-latency native performance at its foundation.
In addition to our long-standing strategic partnership with Confluent, we are also excited to announce partnerships with AWS, Microsoft, Redpanda, and Google, at launch.
Atlas Stream Processing then provides 3 key capabilities required to turn your firehose of streaming data into differentiated customer experiences. Let’s go through these one by one.
Continuous processing
First, developers can now use MongoDB’s aggregation framework to continuously process rich and complex streams of data from event streaming platforms such as Apache Kafka. This unlocks powerful new ways to continuously query, analyze, and react to streaming data without any of the delays inherent in batch processing. With the aggregation framework, you can filter and group data, aggregating high-velocity event streams into actionable insights over stateful time windows, powering richer, real-time application experiences.
Continuous validation
Next, Atlas Stream Processing offers developers robust and native mechanisms to handle incorrect data issues that can otherwise cause havoc in applications. Potential issues include passing inaccurate results to the app, data loss, and application downtime. Atlas Stream Processing solves these problems to ensure streaming data can be reliably processed and shared between event-driven applications.
Atlas Stream Processing:
-
Provides Continuous Schema Validation to check that events are properly formed before processing – for example rejecting events with missing fields or containing invalid value ranges
-
Detects message corruption, and
-
Detects late-arriving data that has missed a processing window.
Atlas Stream Processing pipelines can be configured with an integrated Dead Letter Queue (DLQ) into which events failing validation are routed. This avoids developers having to build and maintain their own custom implementations. Issues can be quickly debugged while the risk of missing or corrupt data bringing down the entire application is minimized.
Continuous merge
Your processed data can then be continuously materialized into views maintained in Atlas database collections. We can think of this as a push query. Applications can retrieve results (via pull queries) from the view using either the MongoDB Query API or Atlas SQL interface. Continuously merging updates to collections is a really efficient way of maintaining fresh analytical views of data supporting automated and human decision-making and action. In addition to materialized views, developers also have the flexibility to publish processed events back into streaming systems like Apache Kafka.
Creating a Stream Processor
Let’s show you how easy it is to build a stream processor in MongoDB Atlas. With Atlas Stream Processing, you can use the same aggregation pipeline syntax for a stream processor that you’re familiar with from the database. Below we’re showcasing a simple stream processing instance from start to finish. It takes just a few lines of code.
First, we’ll write an aggregation pipeline that defines a source for your data, performs validation ensuring data is not coming from the localhost/127.0.0.1 IP address, creates a tumbling window to collect grouped message data every minute, and then merges that newly processed data into a MongoDB collection in Atlas.
Then, we’ll create our Stream Processor called “netattacks” specifying our newly defined pipeline p as well as dlq as arguments. This will perform our desired processing, and by using a Dead Letter Queue (DLQ), will store any invalid data safely for inspection, debugging, or re-processing later.
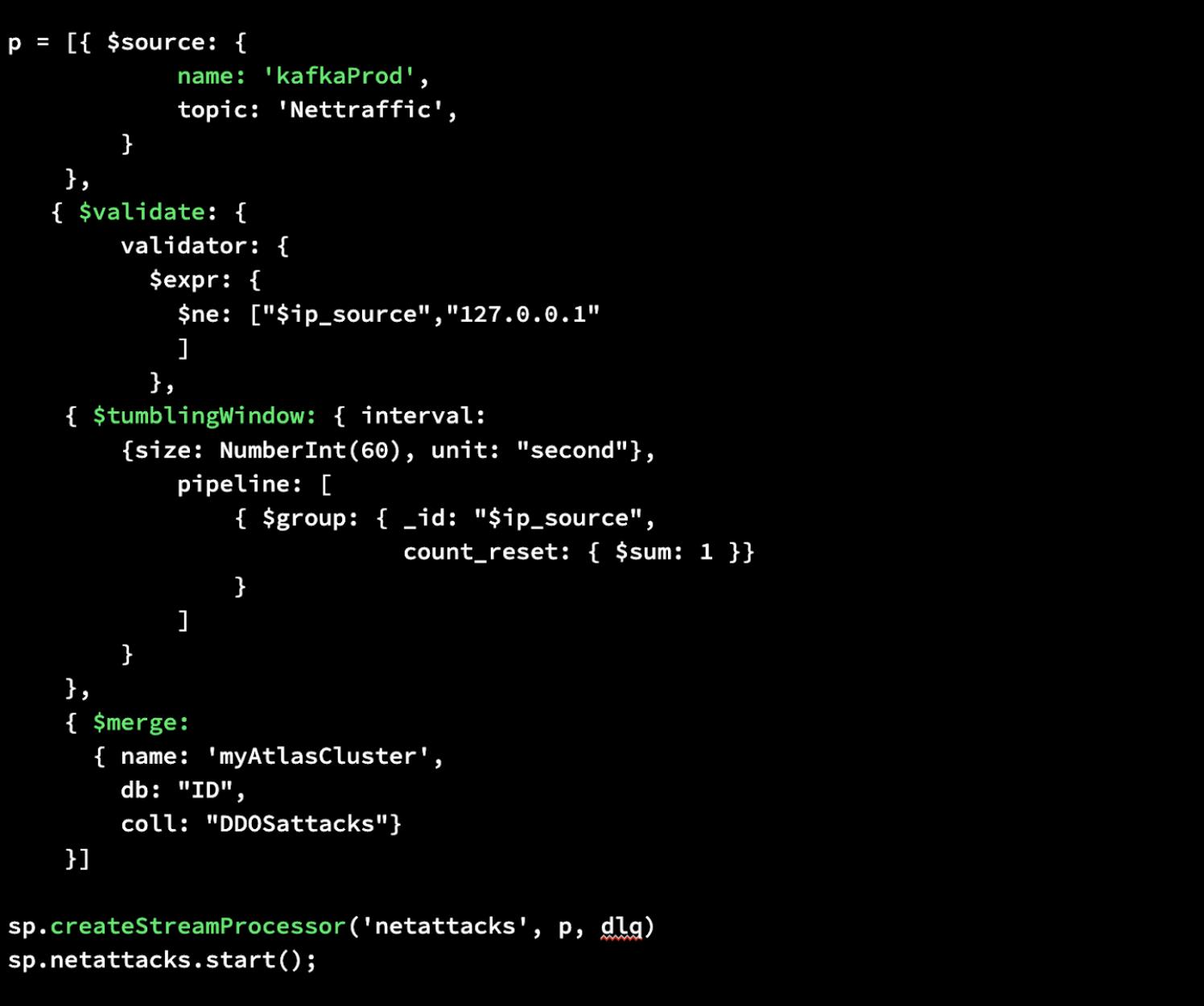
Lastly, we can start it. That’s all it takes to build a stream processor in MongoDB Atlas.
Request early access
We’re excited to get this product into your hands and see what you build with it. Learn more about Atlas Stream Processing and request early access to participate in the private preview once it opens to developers.
New to MongoDB? Get started for free today by signing up for MongoDB Atlas.
Head to the MongoDB.local hub to see where we'll be showing up next.
Safe Harbor
The development, release, and timing of any features or functionality described for our products remains at our sole discretion. This information is merely intended to outline our general product direction and it should not be relied on in making a purchasing decision nor is this a commitment, promise or legal obligation to deliver any material, code, or functionality.