Intel Optane DC Persistent Memory is a non-volatile memory (NVRAM) product that resembles both storage and memory and can be used as either. Like storage, Optane NVRAM retains data after a crash or power outage. Like memory, it sits on the memory bus and can be accessed by CPU using load/store instructions. In certain scenarios, its access latency even approaches that of dynamic random access memory (DRAM).
At MongoDB, we have been thinking about how to use NVRAM in the storage engine. It can be seen as an extension of volatile DRAM, but a denser and a cheaper one. In pursuit of this goal, we extended our storage engine, WiredTiger, with a volatile NVRAM cache that retains frequently used file blocks.
In this article, we share our experience, describe the lessons learned, and evaluate the costs and benefits of this approach.
How to use NVRAM in the storage stack
Optane NVRAM can act as both storage and memory. The persistent memory fabric itself can be packaged as a solid-state drive (SSD), as in Optane SSDs, or as a dual-inline memory module (DIMM) that looks almost like its DRAM counterpart and lives in the same type of slot on the motherboard.
Even when NVRAM is packaged as a non-volatile DIMM (NVDIMM), we can ask the operating system to present it as a block device, put a file system on top, and use it just like regular storage.
Broadly speaking, there are three ways to use NVRAM:
-
As regular storage
-
As persistent memory
-
As an extension to volatile memory
NVRAM as storage
Using NVRAM as regular storage can deliver superior throughput (compared to SSD) for read-dominant workloads, but this approach hinders write-dominant workloads because of Optane NVRAM’s limited write throughput (see the section “Performance properties of Optane NVRAM”). In any case, both the price and density of NVRAM are closer to those of DRAM than to those of SSD, so using it as storage is not recommended.
NVRAM as persistent memory
Imagine that all your data structures live in memory and that you never have to worry about saving them to files. They are just there, even after you quit your application or if it suffers a crash. Although this setup sounds simple, in practice, it is still challenging to program for this model.
If your system crashes and you would like to be able to find your data after restart, you need to name it. A variable name is not sufficient, because it is not unique; thus, you have to restructure your code to make sure your data has persistent identifiers. Persistent Memory Development Kit (PMDK) provides APIs for that.
A more difficult problem is surviving a crash. Your program may crash in the middle of a logical operation on a data structure. For example, suppose you are inserting an item into a linked list, and you have set the source pointer, but the crash occurs before setting the destination pointer. Upon restart, you’ll end up with corrupted data. To make matters worse, even if the logical operation had completed before the crash, the data might have been written only to CPU caches but not persisted to the memory itself.
One solution is to wrap memory operations in transactions; however, programming transactional memory is notoriously difficult. Another solution is to use prepackaged data structures and APIs, but if you are looking to create your own highly optimized data structures, you must implement your own logging and recovery or other mechanisms that protect your data similarly to transactions.
NVRAM as an extension of volatile memory
Somewhat counterintuitively, this option involves disregarding the persistence of NVRAM and using it as a volatile extension of DRAM. Why would you want to do that? Suppose you have a fixed budget to buy extra memory for your system. You can either afford N GB of DRAM or about M*N GB of NVRAM — that’s because NVRAM is denser and cheaper per byte than DRAM (about three times cheaper, at the time of writing). Depending on your application, you might be better off in terms of performance/$$ if you buy additional NVRAM, as opposed to DRAM.
In support of this use case, Intel provides a hardware mechanism, called Memory Mode, which treats NVRAM as “regular” system memory and uses DRAM as its cache. In other words, the hardware will do its best to place frequently used data structures in DRAM, and the rest will reside in NVRAM. The beauty of this mechanism is that it requires absolutely no changes to applications. The downside is that it may perform worse than a custom solution for certain workloads (see section “How NVCache affects performance”).
Our solution is a custom-built volatile cache that resides in NVRAM.
Our architecture
Our NVRAM cache (or NVCache) is a component of the MongoDB storage engine WiredTiger. For persistent storage, WiredTiger organizes data into blocks, where keys and values are efficiently encoded and (optionally) compressed and encrypted. For fast query of its B+-tree data structure, WiredTiger transforms blocks into pages, where keys/values are decoded and indexed. It keeps pages in its DRAM page cache.

Figure 1 shows the architecture of NVCache. NVCache is the new component, and the rest are part of WiredTiger. NVCache sits next to the block manager, which is the code responsible for reading/writing the data from/to persistent storage. Let’s look at each path in turn.
Read path: If the page cache cannot locate the searched-for data, it issues a read to the block manager (1). The block manager checks whether the block is present in NVCache (2), accesses it from NVCache if it is (3), and reads it from disk if it is not (4). The block manager then transforms the block into a page, decrypting and decompressing it if needed, and then hands it over to the page cache (5). It also notifies NVCache that it has read a new block, and NVCache then has the discretion to accept it (6). NVCache stores the blocks in the same format as they are stored on disk (e.g., compressed or encrypted if those configuration options were chosen).
Write path: The write path differs from the read path in that WiredTiger does not modify disk blocks in place. It writes updates into in-memory data structures and then converts them into new pages, which would be sent to disk either during eviction from the page cache or during a checkpoint (7). When the block manager receives a new page, it converts it into a new block, writes the block to storage (8), and informs NVCache (9). NVCache then has the discretion to accept it. Obsolete blocks are eventually freed, at which time the block manager instructs NVCache to invalidate cached copies (10). To avoid running out of space, NVCache periodically evicts less-used blocks. The eviction thread runs once a second.
Overall, this design is straightforward, but making it performant was a challenge. As expected with brand new storage or memory devices, the software must cater to their unique performance properties. In the next section, we focus on these performance features and explain how we adapted our cache to play along.
Performance properties of Optane NVRAM
In low-bandwidth scenarios, the access latency of Optane NVRAM approaches that of DRAM. A small read takes about 160 to 300 nanoseconds, depending on whether it is part of a sequential or a random access pattern1; a read from DRAM takes about 90 nanoseconds.3 Small writes are as fast as in DRAM3 because the data only has to reach the memory controller, where it will be automatically persisted in case of a power loss.
In high-bandwidth scenarios, we usually look at throughput. Sequential read throughput is about 6 GB/s for a single NVDIMM 1,2 and scales linearly as you add more memory modules. (A single 2nd Generation Intel Xeon Scalable processor can support up to six NVDIMMs.) The write throughput is more limited: We observed up to 0.6 GB/s on a single NVDIMM2, and others observed up to 2.3 GB/s.3 Again, if your workload writes to different NVDIMMs, the throughput will scale with the number of modules in your system.
A somewhat troublesome observation about write throughput is that it scales negatively as you add more threads. Write throughput peaks at one or two concurrent threads and then drops as more threads are added.2,3 More importantly, we were surprised to find that, on Optane NVRAM, the presence of writers disproportionately affects the throughput of readers.

Figure 2 shows how the throughput of eight reader threads drops as more concurrent writers are added. Although this effect is present on both DRAM and NVRAM (and certainly on other storage devices), on Optane NVRAM, the effect is much more pronounced. Performance of reads will suffer in the presence of writes. This important observation drove the design of our NVCache.
Throttling writes in caches for Optane NVRam
For a cache to be useful, it must contain popular data. The duties of admitting fresh data and expunging the old fall on cache admission and eviction policies, respectively. Both admission and eviction generate writes, and, because writes hurt the performance of reads on Optane, admission and eviction will interfere with performance of cache retrievals (which involve reads).
Thus, we have a trade-off: On one hand, admission and eviction are crucial to making the cache useful. On the other hand, the write operations that they generate will hamper the performance of data retrievals, thereby making cache less performant.
To resolve this tension, we introduced the Overhead Bypass (OBP) metric, which is a ratio of reads and writes applied to the cache. Keeping this ratio under a threshold allowed us to limit the overhead of writes:
OBP = blocks_looked_up / (blocks_inserted + blocks_deleted)
Intuitively, blocks_looked_up correlates with the benefit of using the cache, whereas the sum of blocks_inserted and blocks_deleted correlates with the cost. NVCache throttles admission and eviction to keep this ratio under 10%. (Our source code is available in the WiredTiger public GitHub repository.)
Without OBP, the sheer overhead of data admission and eviction was quite substantial. To measure this overhead in its purest form, we experimented with workloads that do not stand to benefit from any extra caching, such as those with small datasets that fit into the OS buffer cache (in DRAM) or those that perform so many writes that they quickly invalidate any cached data. We found that using NVCache without the OBP feature caused these workloads to run up to two times slower than without the cache.
Introducing the OBP completely eliminated the overhead and enabled the workloads that stand to benefit from extra caching to enjoy better performance.
How NVCache affects performance
In this section, we’ll look in detail at the performance of workloads with large datasets that stand to benefit from an additional cache.
Experimental system: The following experiments were performed on a Lenovo ThinkSystem SR360 with two Intel Xeon Gold 5218 CPUs. Each CPU has 16 hyper-threaded cores. The system has two Intel Optane persistent memory modules of 126 GB each. For storage, we used an Intel Optane P4800X SSD. We configured our system with only 32 GB of DRAM to make sure that extra memory in the form of NVRAM would be called for.
We present the data with widely used YCSB benchmarks4,5 (Table 1), although we also performed analysis with our in-house benchmarks and reached similar conclusions.
The following charts compare the throughput of YCSB with NVCache, with Intel Memory Mode (MM), and with OpenCAS6 — a kernel implementation of NVRAM-resident cache from Intel. OpenCAS was configured in the write-around mode, which was the best option for limiting the harmful effect of writes.7
Figures 3a-c shows the data in configurations using 63 GB, 126 GB, and 252 GB of NVRAM, respectively.

We make the following three observations:
OpenCAS cache delivers no performance benefit from extra NVRAM. It achieves a similar or better read hit rate as the NVCache but also makes two orders of magnitude more writes to NVRAM, probably because it does not throttle the rate of admission. Writes interfere with performance of reads, which is probably why this cache delivers no performance benefits.
When the dataset size exceeds NVRAM capacity, NVCache provides substantially better performance than Memory Mode. As shown in Figure 3a, NVCache outperforms the memory mode by between 30% (for YCSB-B) and 169% (for YCSB-C). Furthermore, the memory mode hurts YCSB-A’s update throughput by about 18% relative to the DRAM-only baseline, while NVCache does not.
Memory mode performs comparably to NVCache when NVRAM is ample. With 252 GB of NVRAM, all datasets comfortably fit into the NVRAM. Two factors explain why NVCache loses its edge over MM with ample NVRAM: (1) For NVCache, the marginal utility of additional NVRAM is small after 126 GB; NVCache hit rate grows by about 20% when we increase NVRAM size from 63 GB to 126 GB, but only by another 5% if we increase it from 126 GB to 252 GB. (2) While MM allows the kernel buffer cache to expand into NVRAM, NVCache confines it to DRAM, which is also used by the WiredTiger’s page cache. Contention for DRAM limits performance.
Overall, the benefit of a custom NVRAM cache solution is that it provides better performance than the Memory Mode for large workloads. The disadvantage is that it requires new software, whereas MM can be used without any changes to applications.
Performance and cost
In this section, we explore the trade-offs of using Optane NVRAM as a volatile extension of DRAM versus just using more DRAM. To that end, we take a fixed memory budget of 96 GB and vary the fraction satisfied by DRAM and NVRAM as shown in Table 2.

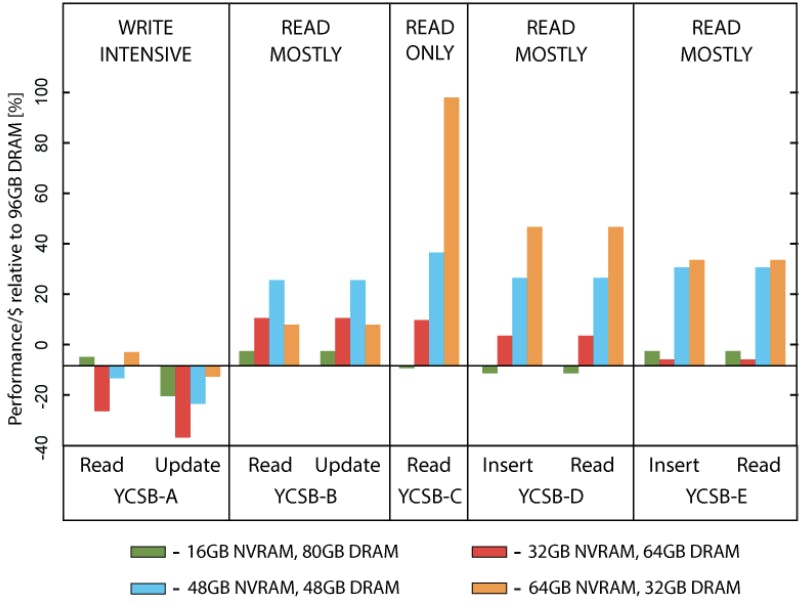
Figure 4 shows the performance of YCSB under these configurations normalized to using 96 GB DRAM and divided by the cost ratio in column 3. In other words, these are performance/$ numbers relative to the DRAM-only configuration. In these experiments, we used only NVCache to manage NVRAM, as it performed comparably to or better than other options.
Positive numbers mean that the performance decreased less than the memory cost. Read-only or read-mostly workloads that benefit from the NVCache experience a positive gain, as expected.
Although in most cases performance predictably drops as the amount of DRAM decreases, YCSB-C in configuration with 64 GB NVRAM and 32 GB DRAM performs better than it does with 96 GB DRAM — so we decrease the system cost and improve performance in absolute terms. This occurs because beyond 32 GB of DRAM, the utility of additional memory (and a larger page cache) is considerably smaller than the loss in performance due to a smaller NVCache.
YCSB-A, whose write intensity prevents it from deriving benefits of any additional caching, suffers the overall loss in terms of performance/$. Its performance drops at a steeper rate than the memory cost as we decrease the amount of DRAM.
We conclude that NVRAM is a cost-effective method of reducing memory cost while balancing the impact on performance for read-dominant workloads. At the same time, even a modest presence of writes can render NVRAM unprofitable relative to DRAM.
References
-
J. Izraelevitz, et al. Basic Performance Measurements of the Intel Optane DC Persistent Memory Module. arXiv:1903.05714.
-
We Replaced an SSD with Storage Class Memory. Here is What We Learned by Sasha Fedorova. The MongoDB Engineering Journal.
-
Jian Yang, et al. An Empirical Guide to the Behavior and Use of Scalable Persistent Memory. USENIX File Access and Storage Conference (FAST 2020).
-
B.F. Cooper, et al. Benchmarking Cloud Serving Systems with YCSB. SoCC '10: Proceedings of the 1st ACM Symposium on Cloud Computing.
-
H.T. Kassa, et al. Improving Performance of Flash Based Key-value Stores Using Storage Class Memory as a Volatile Memory Extension. USENIX Annual Technical Conference (USENIX ATC 21).