The key to successful, long-lasting commerce is knowing your customers. If you truly know your customers, then you understand their needs and wants and can identify the right product to deliver to them—at the right time and in the right way. However, for most B2C enterprises, building a single view of the customer poses a major hurdle due to copious amounts of fragmented data.
Businesses gather data from their customers in multiple locations, such as ecommerce platforms, CRM, ERP, loyalty programs, payment portals, web apps, mobile apps and more. Each data set can be structured, semi-structured or unstructured, delivered as stream or require batch processing, which makes compiling already fragmented customer data even more complex. This has led some organizations to bespoke solutions, which still only provide a partial view of the customer.
Siloed data sets make running operations like customer service, targeted marketing and advanced analytics—such as churn prediction and recommendations—highly challenging. Only with a 360 degree view of the customer can an organization deeply understand their needs, wants and requirements, as well as how to satisfy them. A single view of that 360 data is therefore vital for a lasting relationship.
In this blog, we’ll walk through how to build a single view of the customer using MongoDB’s database and Cogniflare’s Calledio Customer 360 tool. We’ll also explore a real-world use case focused on sentiment analysis.
Building a single view with Calleido's Customer 360
With a Customer 360 database, organizations can access and analyze various individual interactions and touchpoints to build a holistic view of the customer. This is achieved by acquiring data from a number of disparate sources. However, routing and transforming this data is a complex and time-consuming process.
Many of the existing Big Data tools often aren’t compatible with cloud environments. These challenges inspired Cogniflare to create Calleido.
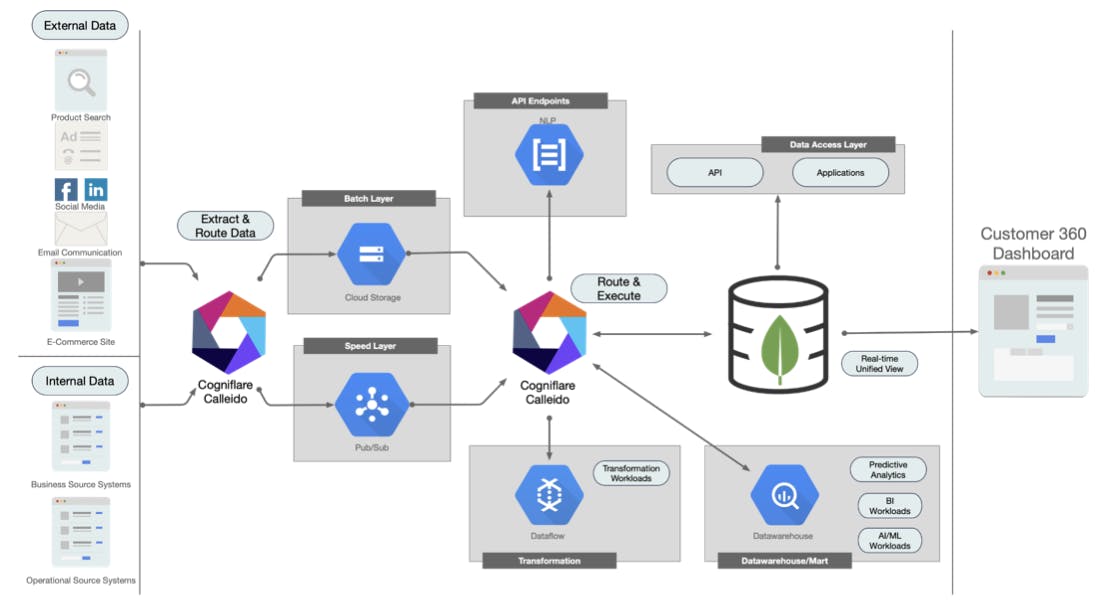
Calleido is a data processing platform built on top of battle-tested open source tools such as Apache NiFi. Calleido comes with over 300 processors to move structured and unstructured data from and to anywhere. It facilitates batch and real-time updates, and handles simple data transformations.
Critically, Calleido seamlessly integrates with Google Cloud and offers one-click deployment. It uses Google Kubernetes Engine to scale up and down based on the demand, and provides an intuitive and slick low-code development environment.
A real-world use case: Sentiment analysis of customer emails
To demonstrate the power of Cogniflare’s Calleido, MongoDB Atlas, and the Customer 360 view, consider the use case of conducting a sentiment analysis on customer emails.
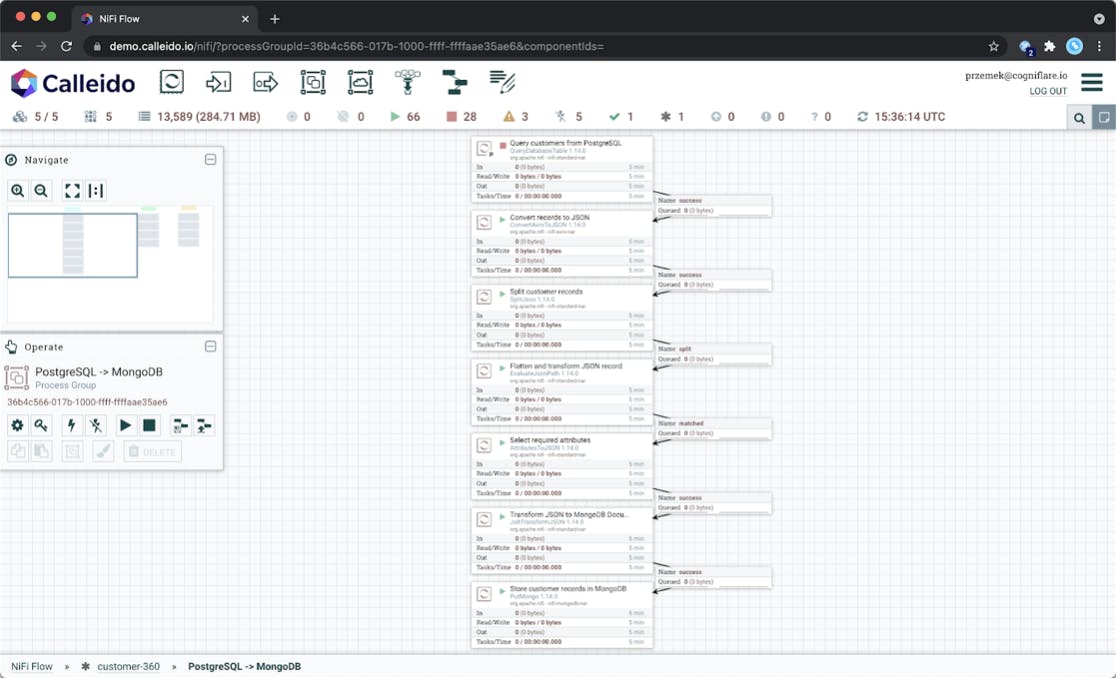
To streamline the build of a Customer 360 database, the team at Cogniflare created flow templates for implementing data pipelines in seconds. In the upcoming sections, we’ll walk through some of the most common data movement patterns for this Customer 360 use case and showcase a sample dashboard.
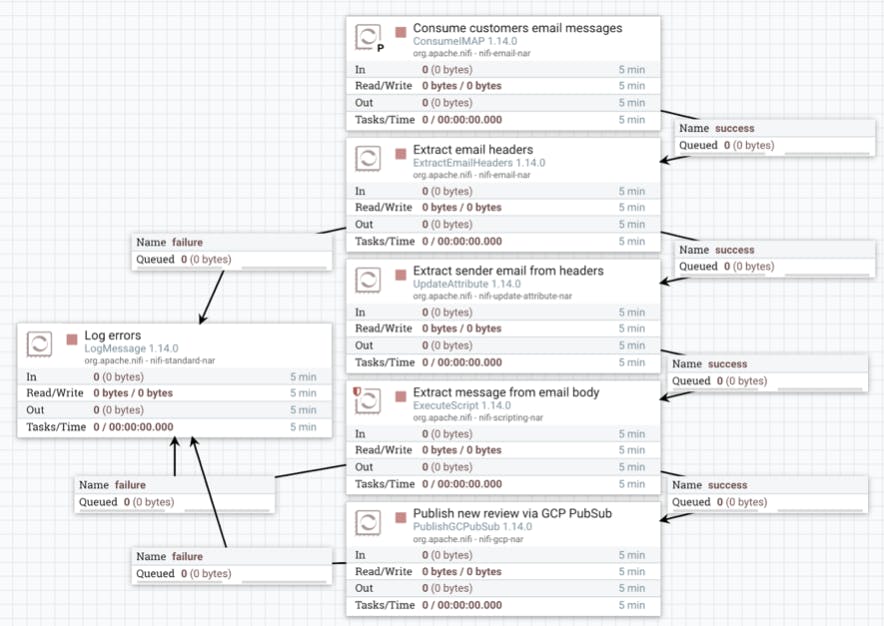
- The flow commences with a processor pulling IMAP messages from an email server (ConsumeIMAP). Each new email that arrives into the chosen inbox (e.g. customer service), triggers an event.
- Next, the process extracts email headers to determine topline details about the email content (ExtractEmailHeaders).
- Using the sender's email, Calleido identifies the customer (UpdateAttribute) and extracts the full email body by executing a script (ExecuteScript).
- Now, with all the data collected, a message payload is prepared and published through Google Cloud Platform (GCP) Pub/Sub (Kafka can also be used) for consumption by downstream flows and other services.
- The GCP Pub/Sub messages from the previous flow are then consumed (ConsumeGCPPubSub). This is where the power of MongoDB Atlas integration comes in as we verify each sender in the MongoDB database (GetMongo). If a customer exists in our system, we pass the email data to the next flow. Other emails are ignored.
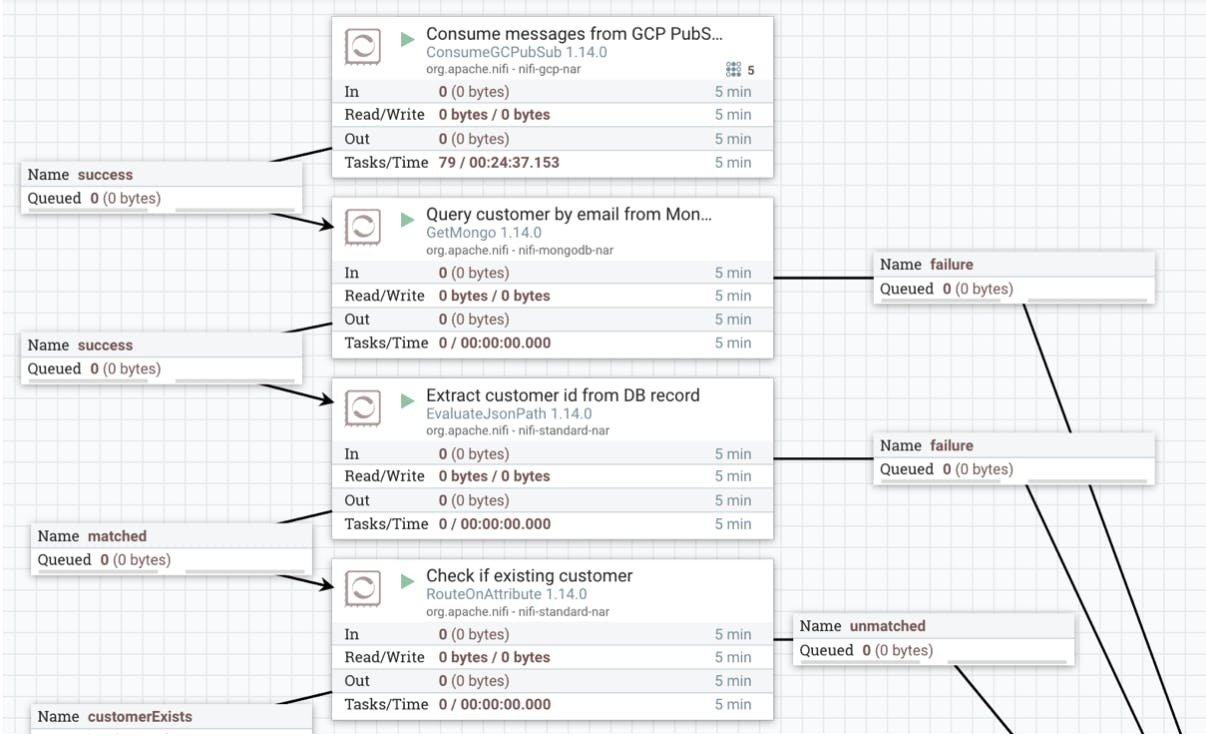
- Analysis of the email body copy is then conducted. For this flow, we use a processor to prepare a request body, which is then sent to Google Cloud Natural Language AI to assess the tone and sentiment of the message.
- The results from the Language Processing API then go straight to MongoDB Atlas so they can be pulled through into the dashboard.
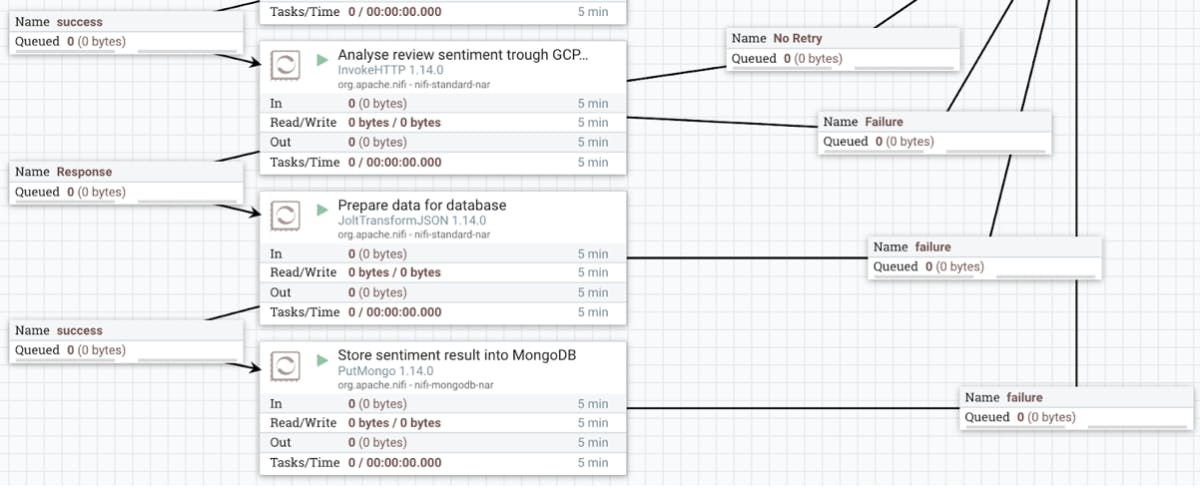
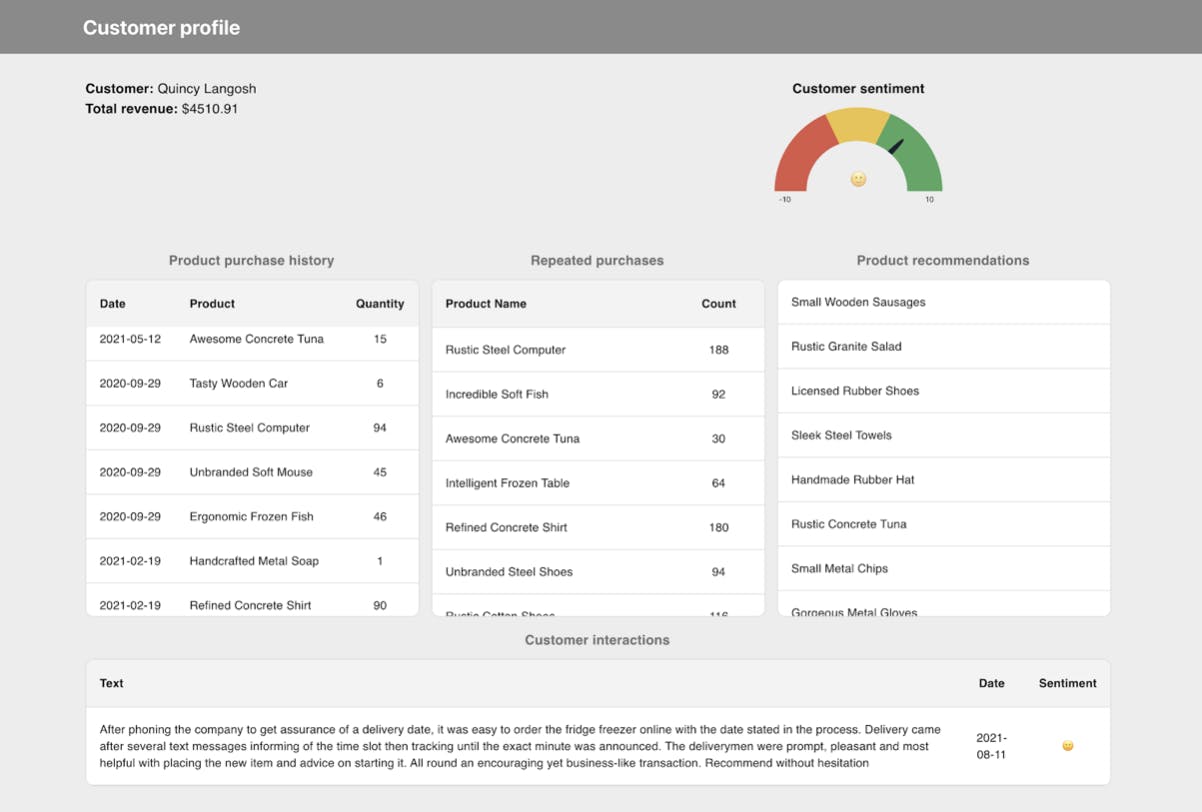
End result in the dashboard:
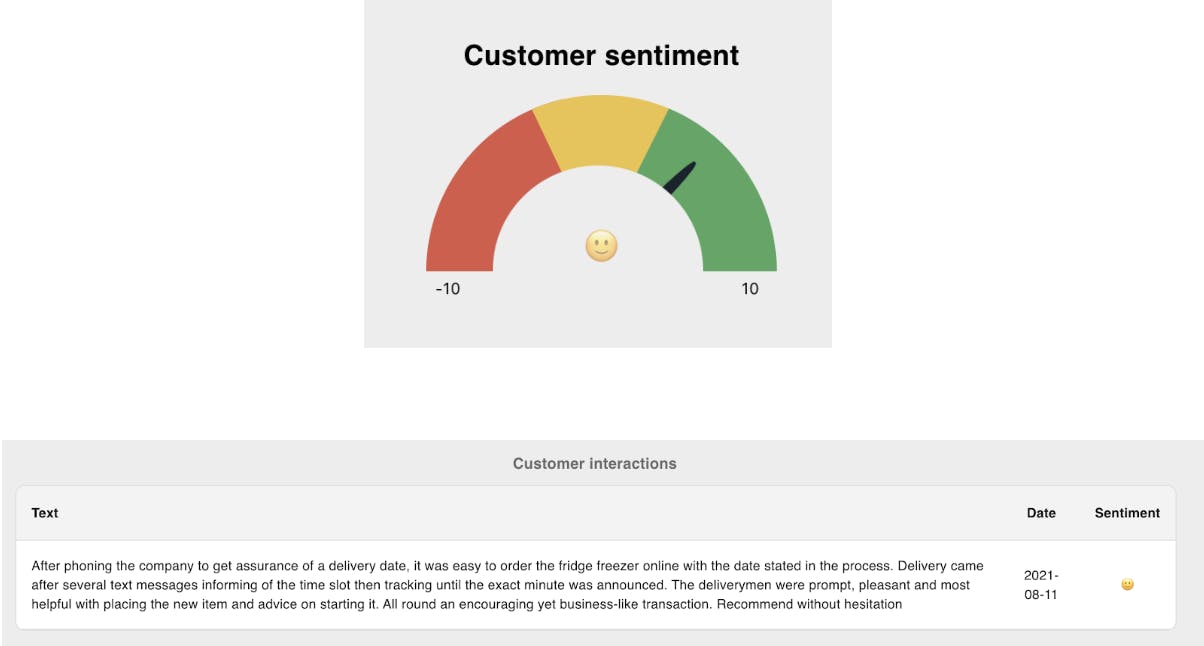
The Customer 360 database can be used in internal back-office systems to supplement and inform customer support. With a single view, it’s quicker and more effective to troubleshoot issues, handle returns and resolve complaints.
Leveraging information from previous client conversations ensures each customer is given the most appropriate and effective response. These data sets can then be fed into analytics systems to generate learnings and optimizations, such as associating negative sentiment with churn rate.
How MongoDB's document database helps
In the example above, Calleido takes care of copying and routing data from the business source system into MongoDB Atlas, the operational data store (ODS).
Thanks to MongoDB’s flexible data structure, we can transfer data in its original format, and subsequently implement necessary schema transformations in an iterative manner. There is no need to run complex schema migrations. This allows for the quick delivery of a single view database.
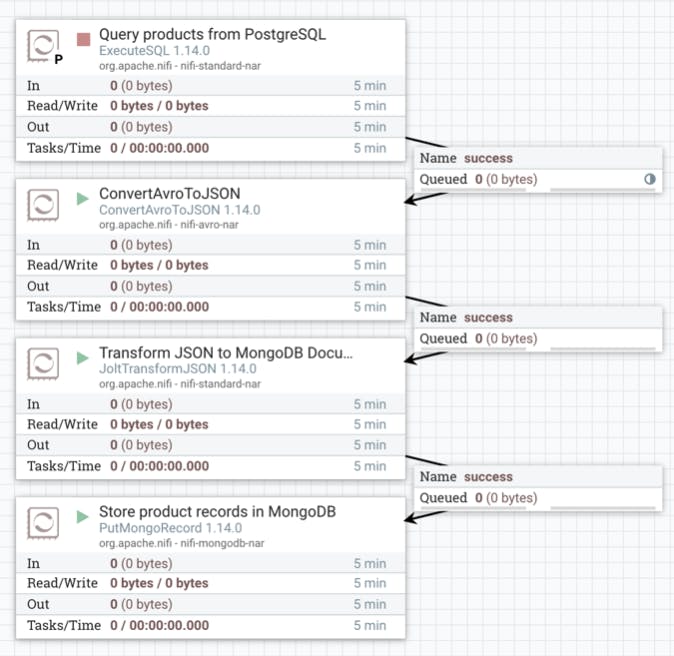
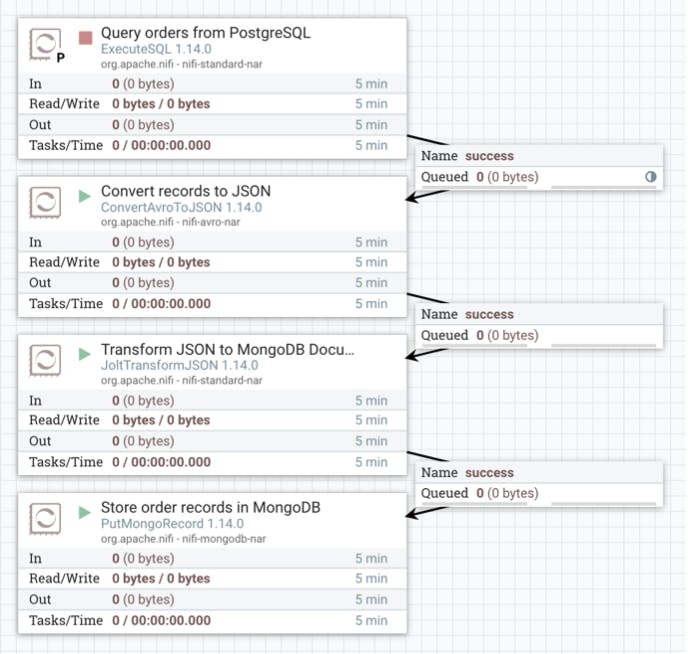
Calleido allows us to make this transition in just a few simple steps.
- The tool runs a custom SQL query (ExecuteSQL) that will join all the required data from outer tables and compile the results in order to parallelize the processing.
- The data arrives in Avro format, then Calleido converts it into JSON (ConvertAvroToJSON) and transforms it to the schema designed for MongoDB (JoltTransformJSON).
End result in the Customer 360 dashboard:
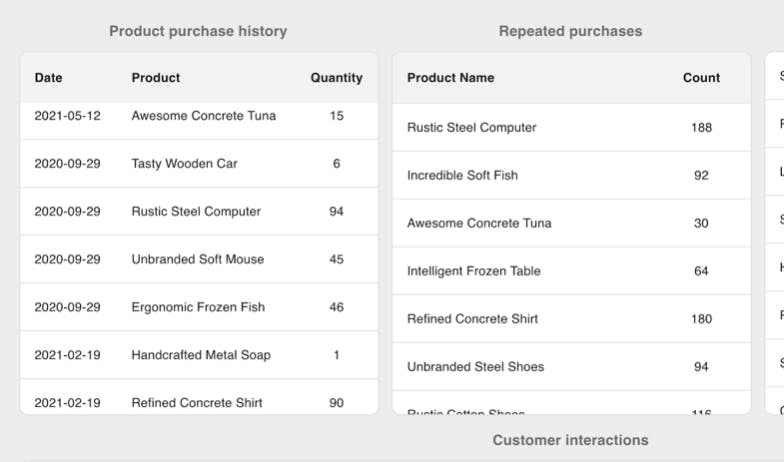
MongoDB Atlas is the market-leading choice for the Customer 360 database. Here are the core reasons for its world-class standard:
- MongoDB can efficiently handle non-standardized schema coming from legacy systems and efficiently store any custom attributes.
- Data models can include all the related data as nested documents. Unlike SQL databases, MongoDB avoids complicated join queries, which are difficult to write and not performant.
- MongoDB is rapid. The current view of a customer can be served in milliseconds without the need to introduce a caching layer.
- The MongoDB flexible schema model enables agility with an iterative approach. In the initial extraction, the data can be copied nearly exactly as its original shape. This drastically reduces latency. In subsequent phases, the schema can be standardized and the quality of the data can be improved without complex SQL migrations.
- MongoDB can store dozens of terabytes of data across multiple data centers and easily scale horizontally.
- Data can be shared across multiple regions to help navigate compliance requirements.
- Separate analytics nodes can be set up to avoid impacting performance of production systems.
- MongoDB has a proven record of acting as a single view database, with legacy and large organizations up and running with prototypes in two weeks and into production within a business quarter.
- MongoDB Atlas can autoscale out of the box, reducing costs and handling traffic peaks.
- The data can be encrypted both in transit and at rest, helping to accomplish compliance with security and privacy standards, including GDPR, HIPAA, PCI-DSS, and FERPA.
Upselling the customer: Product recommendations
Upselling customers is a key part of modern business, but the secret to doing it successfully is that it’s less about selling and more about educating. It’s about using data to identify where the customer is in the customer journey, what they may need, and which product or service can meet that need.
Using a customer's purchase history, Calleido can help prepare product recommendations by routing data to the appropriate tools such as BigQuery ML. These recommendations can then be promoted through the call center and marketing teams for both online or mobile app recommendations.
There are two flows to achieve this: preparing training data and generating recommendations:
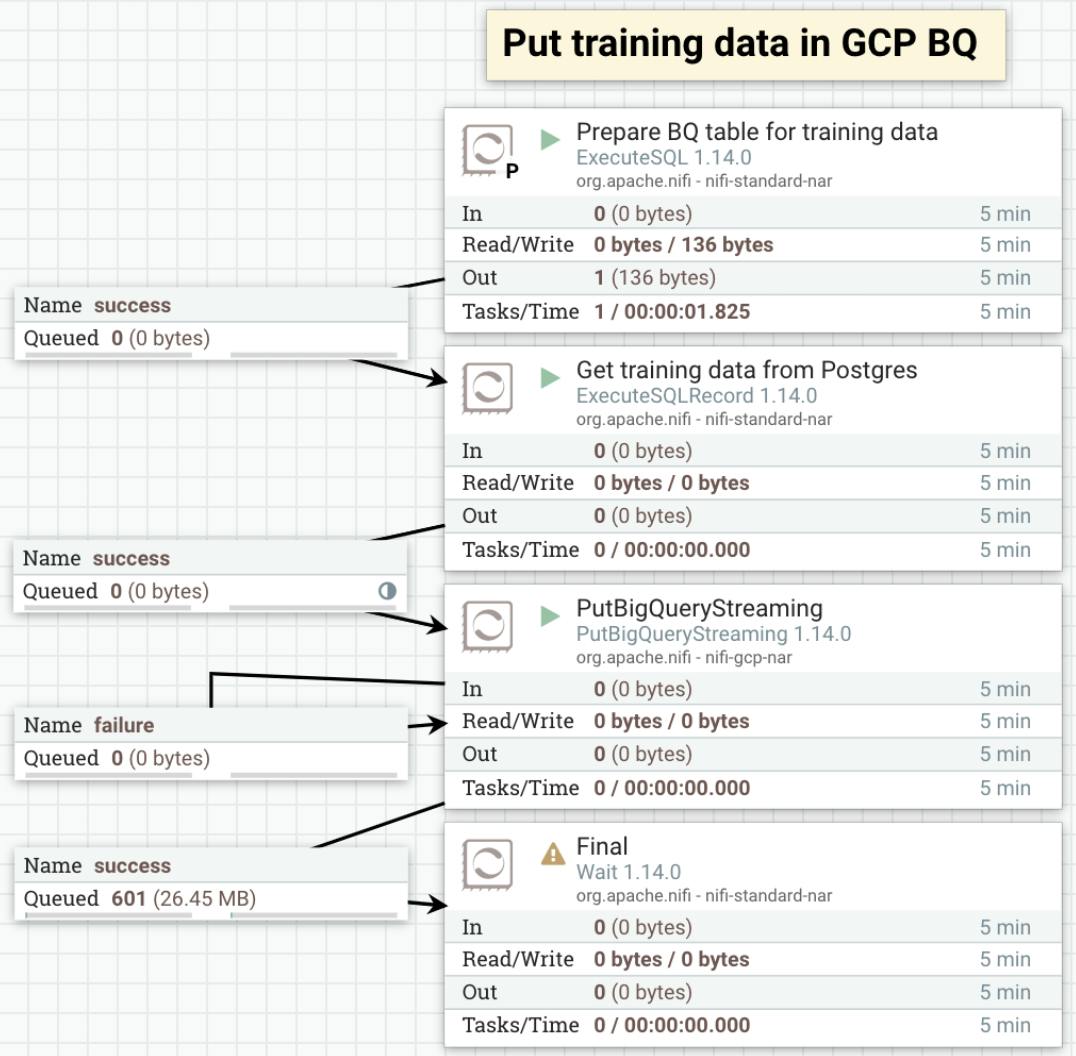
Preparing training data
- First, appropriate data from PostgreSQL to BigQuery is transferred using the ExecuteSQL processor. The data pipeline is scheduled to execute periodically.
- In the next step, appropriate data is fetched from PostgreSQL, dividing it to 1K row chunks with the ExecuteSQLRecord processor.
- These files are then passed to the next processor which uses load balancing enabled to utilize all available nodes.
- All that data then gets inserted to a BigQuery table using the PutBigQueryStreaming processor.
Generating product recommendations
Next, we move on to generating product recommendations.
- First, you must purchase Big Query capacity slots, which offer the most affordable way to take advantage of BigQuery ML features.
- Here, Calleido invokes an SQL procedure with the ExecuteSQL processor, then ensures that the requested BigQuery capacity is ready to use.
- The next processor (ExecuteSQL) executes an SQL query responsible for creating and training the Matrix Factorization ML model using the data copied by the first flow.
- Next in the queue, Calleido uses the ExecuteSQL processor to query our trained model to acquire all the predictions and store them in a dedicated BigQuery table.
- Finally, the Wait processor waits for both capacity slots to be removed, as they are no longer required.

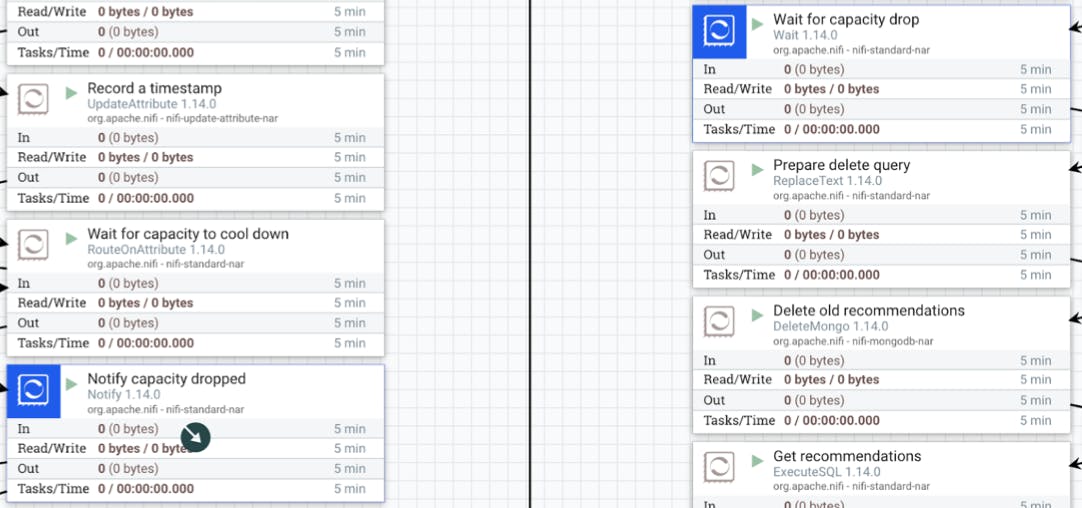
- Then, we remove old recommendations through the power of two processors. First, the ReplaceText processor updates the content of incoming flow files, setting the query body. This is then used by the DeleteMongo processor to perform the removal action.
- The whole flow ends with copying Recommendations to MongoDB. The ExecuteSQL processor fetches and aggregates the top 10 recommendations per user, all in chunks of 1k rows. Then, the following two processors (ConvertAvroToJSON and ExecuteScript) prepare data to be inserted into the MongoDB collection, by the PutMongoRecord processor.
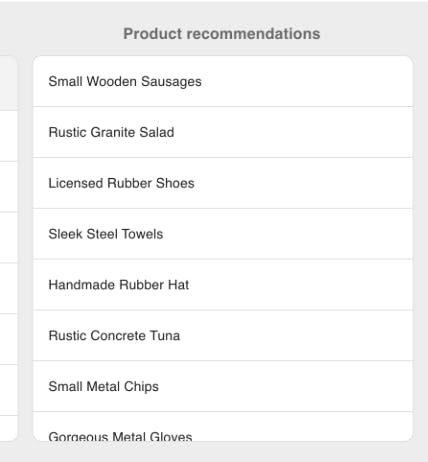
End result in the Customer 360 dashboard (the data used here in this example is autogenerated):
Benefits of Calleido's 360 customer database on MongoDB Atlas
Once the data is available in a centralized operational data store like MongoDB, Calleido can be used to sync it with an analytics data store such as Google BigQuery. Thanks to the Customer 360 database, internal stakeholders can then use the data to:
- Improve customer satisfaction through segmentation and targeted marketing
- Accurately and easily access compliance audits
- Build demand planning forecasts and analyses of market trends
- Reward customer loyalty and reduce churn
Ultimately, a single view of the customer enables organizations to deliver the right message to prospective buyers, funneling those at the brand awareness stage into the conversion stage and ensures retention and post sales mechanics are working effectively.
Historically, a 360 view of the customer was a complex and fragmented process, but with Cogniflare’s Calleido and MongoDB Atlas, a Customer 360 database has become the most powerful and cost efficient data management stack that an organization can harness.