When solving concurrency problems in software, the simplest solution is often to make the trickiest part of the problem serial. Here at MongoDB, this is exactly the approach we took to implement a commit queue, where engineers submit code changes to be tested and then merged into a repository. This worked well for many smaller repositories, but for large ones such as the MongoDB Server, testing submissions one at a time proved to be too slow, with engineers sometimes waiting hours for their code to finally make it into the repository. To solve this challenge, we introduced some speculative execution on top of our original approach, which reduced the wait time for a typical week by 62%.
Background
Many of the engineers at MongoDB submit their code changes to a commit queue, which runs a basic set of tests on these changes before merging them to the correct repository. The main difference between the commit queue running the tests and an engineer running the tests is that the commit queue tests with the latest changes to the code base, whereas an engineer has checked out the code base at some point in the past. To ensure that it has the latest changes, the commit queue tests only one set of changes at a time before either merging the changes if the tests pass, or rejecting them and notifying the author if the tests fail. This serial approach makes the system easy to understand, but it also presents an optimization opportunity to reduce the time spent waiting for tests to start.
Design Approach
Parallelization
The only part of this system we needed to keep serial was the part that merged changes into the repository, because this ensures that changes would be merged in the same order in which they were submitted. By far, the slowest part of the commit queue is actually running the tests, and this is the work that we wanted to split among multiple machines.
Let’s assume as an example that all submissions to the commit queue take 10 minutes to run. Let’s also assume that in one day there are 30 submissions to the commit queue at roughly the same time. With the previous requirement that the queue runs serially, this means it would take 300 minutes to get through all the submissions. If we parallelize testing the submissions among 30 machines, it would take only 10 minutes of actual time from when the last change was submitted to get through all the submissions.
Speculative Execution
With a serial queue, each successful submission checks out the latest code in the repository, applies its changes, runs tests, then commits the code back to the repository before the next submission starts. If we do these steps in parallel however, checking out the latest code in the repository will not include the changes from submissions that would have merged before the one being tested. Parallelizing our tests requires some extra steps to ensure that submissions run tests with the code changes from prior submissions.
In order to know what code changes should be applied to which tests, the commit queue must still maintain the concept of an order for each submission. That way, the third entry in the queue will know that it must apply the changes from the first and second entries, in addition to its own code changes. If any test for a submission fails, it’s rejected from the queue and any submissions after it are rerun without the code changes from the one that failed. If all tests for a submission finish running, the submission will wait to be merged until the one immediately in front of it is merged.
Performance Considerations
Testing with merged code changes like this requires that most of the tests pass; otherwise the system will do a lot more work than it would have done if it tested submissions one at a time, and we lose all the benefits from parallelism. In the worst-case scenario where nothing passes, the nth submission in the queue would need to be restarted each time something in front of it fails, leading to i=0ni = n(n+1)2total times that any submission is run. This means that if engineers add 10 submissions to the commit queue, the new parallel approach runs tests as many as 55 times, whereas with the old serial approach the tests would always run 10 times.
Maybe this worst-case scenario isn’t a big deal if the majority of submissions pass (and at MongoDB, 85% of them do). However we’d like to guarantee that an unusually bad day doesn’t make the machines running the tests do an excessive amount of unneeded work. To make this guarantee possible, we inserted a checkpoint into the queue, so that only the batch of submissions in front of the checkpoint are running tests. In the example of 10 submissions to the queue, placing the checkpoint after submission No. 3 would mean that the first three submissions start running tests while submissions No. 4 and later wait until the first three finish. It’s totally possible that everything still fails, but adding this checkpoint prevents us from doing too much extra work. With the checkpoint, a queue of length n would run f * (f +1)2*n \ f + (n % f) * n % f +12total submissions, where f is the position of the checkpoint, \ is the integer division operator, and % is the modulus operator. If engineers add 10 submissions to the queue and the checkpoint is after submission No. 3, this hybrid approach would run tests as many as 19 times, compared with 55 with a fully parallel and 10 with a fully serial approach.
The following infographic helps visualize this example. Colors represent the current status of the submission: green means successful, red means failed, yellow means in progress, and gray means not yet started.

Results
The graph below depicts the average length of time a submission would wait before it started running tests for a representative week when processing submissions serially.

Contrast these times with the graph below, which shows a representative week with the hybrid approach.
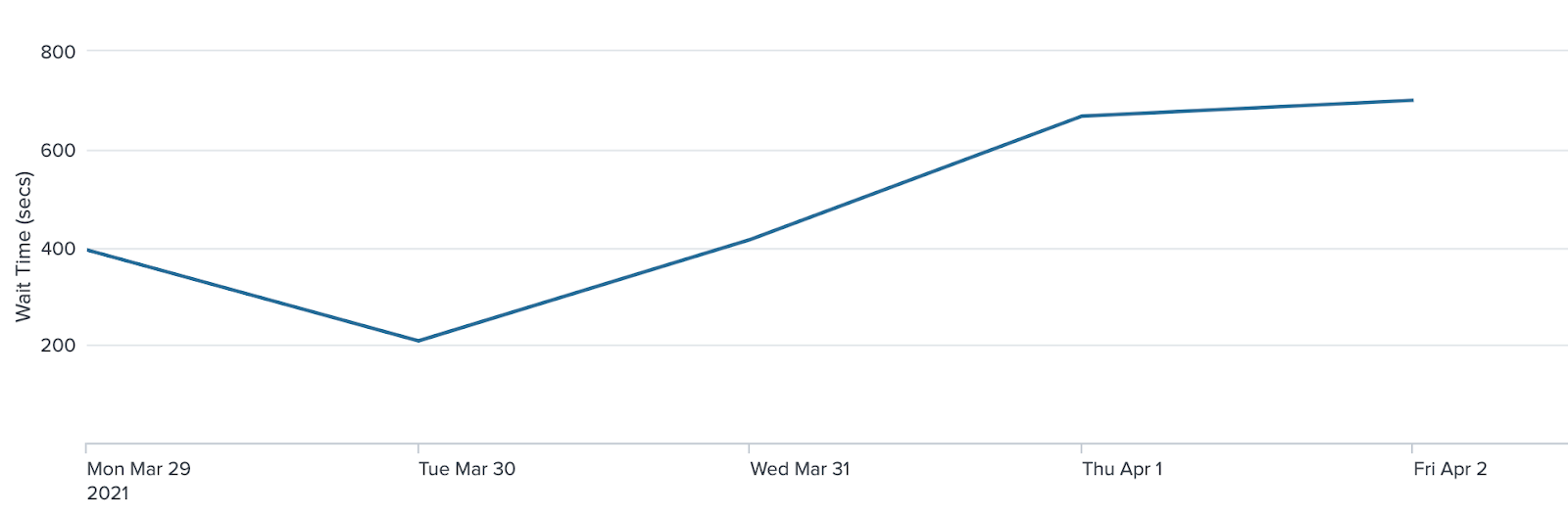
For the depicted weeks, the overall average time dropped from 1,238 seconds with the serial approach to 469 seconds with the hybrid approach — a reduction of 62%.
Conclusion
With this hybrid approach of parallelizing the longest-running parts of the system but keeping key parts serial, we were able to reap the benefits of each approach. We saw drastic reductions in wait times while still maintaining the concept of an ordering for our commit queue. What led us to this approach were the requirements that the result should be noticeably faster for typical sizes of the problem (a queue with one to nine submissions), but could not be drastically slower in the worst-case scenario. These two guiding principles will often yield to designs that work well in real-world scenarios, even though they may not handle all edge cases gracefully.