Legacy data migrations imply a change in the status quo. More often than not, when an organization finally undertakes a thorough analysis of its technology landscape, it arrives at the same decision: to do nothing. It is an understandably daunting task to upgrade or replace 20+ year-old applications and their database counterparts. But there are good reasons, beyond the tri-annual hardware upgrade, to propel those legacy monoliths of the 1990s into the 21st century.
Companies that prevailed—and even triumphed—in the volatile spring of 2020 were those that transitioned to a more flexible usage model and were therefore able to adjust their business models more rapidly and reliably. MongoDB’s client, Sanoma, was one of the winners. Sanoma was able to scale from 3,000 to 150,000 users within 24 hours, without any service interruption.
Innovation and modernization go hand in hand. However, while modernization can sadly occur without innovation, the opposite is simply not possible.
A bit of history
The concept of bringing data together through online data layers (ODL) or operational data stores (ODS) isn't new or specific to MongoDB. Accessing legacy systems, bringing data together, and making it all more easily accessible was a common goal even 20 years ago, and led to the search for the golden source of truth (i.e. the definitive master source for any given entity). This search proved elusive early on due to the hurdles involved with bringing data from diverse, over-structured relational constructs to a sole target called Operational Data Store (ODS) or Online Data Layer (ODL). The industry’s first attempts began with Object-oriented databases, then with the dead end of XML data stores. (In my personal opinion, Xquery and Xpath were never meant for real developers). After both endeavors failed, then came the wave of Apache efforts I like to call “Hadoop Solves the Planet,” in which companies dumped all their structured data onto a big-data treasure trove. Unfortunately, this resulted in a data desert rather than the data lake everybody was hoping for, since organizations then had to scramble to build a concept for secondary indexing, data dictionaries, and more, on top of having to rebuild the sensible structures they lost.
In the 2010s, the document model, in conjunction with JSON notation, emerged as the new de facto standard. MongoDB release 3.x introduced the combination of ACID (atomicity, consistency, isolation, durability) and compliance with a broad range of data types (in BSON, for those in the know). Soon, the MongoDB team started implementing additional features of relational heritage: secondary indexing, ACID transactions, aggregations and manipulations of data in site, materialized views, joins, unions... the list goes on.
Where we are now
MongoDB documents can be enriched through different means and channels without touching the content — the consistency of all data and data lineage is implicitly guaranteed. A typical example is the extraction of a delivery address through a supply chain application and a billing address through an enterprise resource planning system. In many cases, those two systems have different requirements. MongoDB documents simply keep both instantiations intact and can even hold multiples of each attached to one single client profile without the need to complete loads and transformations, foreign keys, and all the other ingredients of the relational past. MongoDB simply adds and leverages other sources without destroying their context.
MongoDB delivers an ODS and ODL experience while streamlining the time-consuming journey of replacing legacy application code.The data platform of true modernization and innovation has arrived!
How your company can get here
The entire journey can be summarized in four simple steps:
- Analysis: Where do I start my data journey to drive the fastest value?
- Scaffolding: How do I get my data out of the existing platform and bridge it to the new platform?
- Coding: How do I enter the world of adjusting and adapting my applications landscape?
- Innovation: Which are the easiest targets for my company to start achieving true innovation?
The following sections answer these four questions and provide you with a starting point for your journey toward a new and improved solution landscape.
Step 1: Analysis of your existing solution landscape
Data Provisioning
Data provisioning—the act of bringing data from source system(s) to target system—is actually the easy part of this step. Opinions may vary as to the very best approach, but most existing models for streaming data in real time make the process elegant and allow for a business-driven decision from real-time replication on one end to communicate with the batch of .CSV files on the other end.
Application onboarding
More exciting is the application onboarding phase, inclusive of the selection and design of initial data domains. Here, simple mechanisms derived from the classic priority concepts can assist—and yes, they existed long before computers.
Data domains already exist in objects in the business logic represented through their objects in the various programming languages. But even the most talented application developer deals with constant changes which leads to compromises in those objects and can obfuscate the original clarity in their design so the objects may hide in plain sight. Unearthing those gems and aligning them to the ODS is the most important step towards true legacy modernization.
The most simple solution is actually the most practical one: load an object with the existing software and persist it into a MongoDB collection. The effort of persisting the object results in two lines of code that can be easily added. The location of the two lines of code (first line one opens connection to database; second line one persists the object) does not matter as long as it is in a place after the object is built out. This is the first time you will see the beauty of MongoDB and MQL at work. You really have to do nothing for the object itself—e.g. no decomposition or abstraction layer. MongoDB takes care of it for you. When looking at the object in the MongoDB database, e.g. using MongoDB Compass, you will realize that it already looks a lot like the domain object you wanted. The actual task to map objects to domains, or subset of domains, is now mostly driven by the application use case.
Tip: How to leverage application mapping to accelerate onboarding
In the model below, which was taken from the financial industry but can easily be adopted across industries, we identify the data domains in various applications and map their behavior to the effort it takes to locate them as well as their importance to the app.
First, each domain gets a rating for its object complexity, where “complexity” is defined by the implementation team. This is similar to the concept of “poker” in a development sprint. Second, each data domain must be located in the application content. Then, it’s tally time.
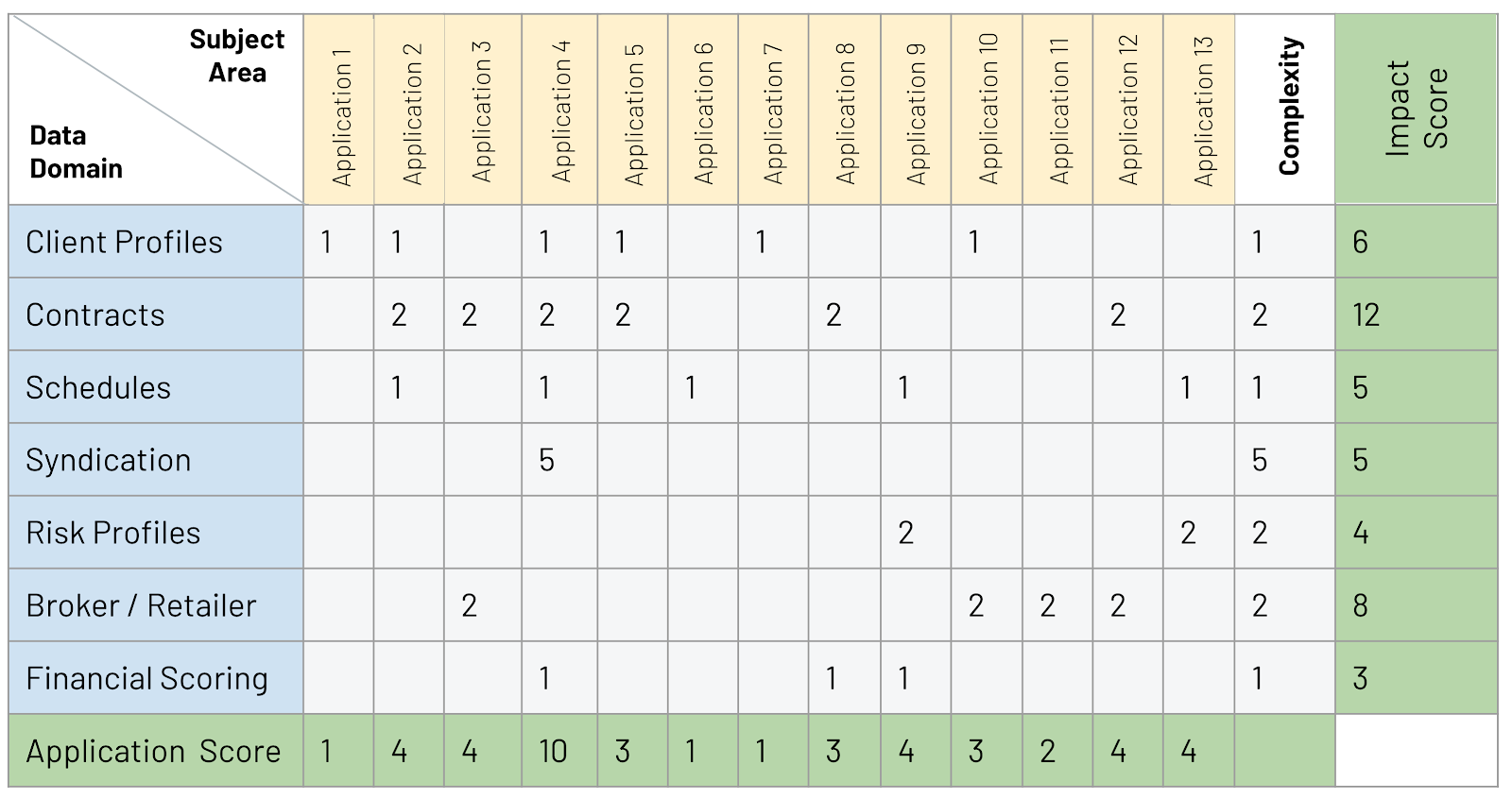
As we can see in the example above, the concept of schedules looks quite easy but is superseded by the client profiles which have a touch more application context (spoiler: those always come out on top). Based on the combination of complexity and the number of data domains affecting an application, we can now easily achieve the model below.
-46zjaihd1v.png)
Agile is your friend and, assuming a certain “point capacity,” the applications fall into place for their conversion schedule in a quite neutral fashion. The development team will then start with low hanging fruit. As soon as application 1, 6 and 7 are ported, we’re in business in a new modern landscape. Along the journey, the domains will get cleaned up naturally as we do not have the static corsage of the RDBMS table designs.
Step 2: Scaffolding
Scaffolding is the art of building a bridge that can hold people as they cross it, then immediately dissipate once they step off. But for that critical time, it needs to hold. The same is true for the connectivity between a legacy system and a new data platform.
Starting with the first sprint, we have data residing in the MongoDB data platform. If the data is limited to new applications and resides exclusively in MongoDB, nothing needs to be done. However, as shown in the client profiles example above, there may be dependencies to consider. The synchronization between the legacy database and the new MongoDB platform can be easily arranged using microservices and the same concepts used for the initial loading of data. Synchronization can also be achieved through “the gate” if only READ data is needed during the first sprint, or if you’re already dealing with WRITE and the requirement to synchronize those writes back to a legacy system.
- Streaming: A streaming based solution is a great option for uni-directional operations that allow read only in the most simple way.
- Service: Selecting a simple, tiny microservice is a good option for the use case where data needs to be selectively written. It works using the document model on the MongoDB side, but can still push necessary updates back to the legacy system, and vice-versa. The great news is that this service potentially exists already, as it requires nothing more than using the old database interface from the legacy application on one side and the new, easy-to-digest JSON document format on the MongoDB side. If both databases are ACID-compliant, any transaction is automatically treated as a normal application interaction on both sides.
- “Y-Loader”: Another option is a true “Y-loader,” where all transactions are written in sync to both databases in parallel, and the actual transaction is only considered committed when both systems report their commit and completion. Simple two-phase protocols (write to both, wait five seconds, read both to validate and, if in sync, commit to application) are available as ready-made services through various distributed transaction coordinators, but often it’s easier to use the existing data access in the application. In that case, the new data path to MongoDB is in parallel, and a simple redundant checkpoint (which the application logic would have had for the legacy path anyway) is expanded for this purpose.
Step 3: Coding
The coding with the new domain data model, as well as the MongoDB flexible document model as the underlying base, will immediately impact the coding for the business logic and application development. The operative word is immediately. As the data gets unlocked with the initial persistence of the code object to the MongoDB collection, the developer is simultaneously able to code based on business requirements. Developers will no longer be hindered by reference and requirements of object mappers. As the objects are represented through the MongoDB idiomatic drivers, each programming object resides directly in the data collection; in reverse, any changes to the business logic object will be naturally represented—code-free—in the MongoDB collection.
A single blog post can't resolve all open questions and edge cases. Each application, client, and data interface is unique. Databases possess historic technical debt and implicit assumptions that become lost in generations of developers over time. “Do not touch this section—not sure what it does but last time we tried all hell broke loose…” is often-heard advice around the organizational water cooler. But the key lesson? There are many different templates available and very simple methods of quickly taking the lead to significant success.
For example, a German client, who was stuck in a combination of IBM DB2 (mainframe and distributed) with a significant Hadoop footprint, was amazed when they realized they could “lift” their data one microservice at a time. This resulted in business requirements shifting from “impossible to do” for some requested queries to “completed in under one second” within a single week of a proof-of-concept. This is no exception. Cases and changes like these are made daily, reinforcing Mark Twain’s sage advice that “The secret of getting ahead is getting started."
Step 4: Innovation
As the migration from the legacy environment continues, innovation will be the new focus.
The unlocking of previously siloed data allows immediate coupling of real-time data with machine learning platforms for various purposes: e.g. scoring for financial decision-making, personalization for retail, or optimization of production processes in the IOT context. New applications and solutions can easily be created on top of the unleashed data, even with various programming languages, direct real-time dashboards created with MongoDB Charts, and different paradigms (again, MongoDB’s idiomatic drivers do magic!)
At this time, the discussion with the product owners in your squads and tribes (trying to be real modern here) begins with the question“What is the highest priority component to change?” and “What function is required to enable this change?”
Is it worth waiting much longer? The real question is: why did we all not start sooner? It’s time to begin integrating the list of features you always dreamed of having, but never dared to pursue. The MongoDB team is here to help you get started.
Reach out today and let’s discuss the best path forward.
To learn more about modernizing to MongoDB, click here.